正如互联网架构演进所讲的,微服务给我们带来许多好处,但同时也带来许多问题,微服务的监控便是其中之一。
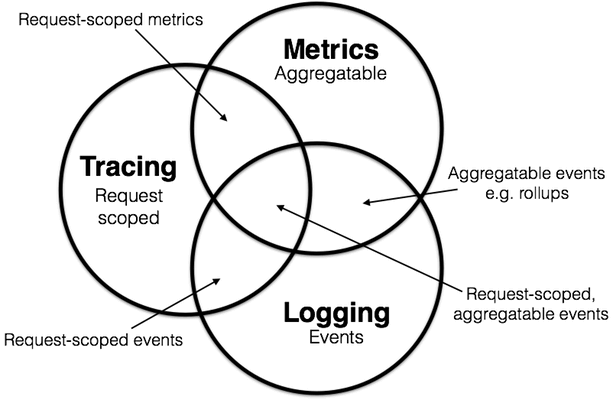
metrics-tracing-and-logging 文中提到微服务监控包括日志、指标、追踪,三者相辅相成。
-
指标:其特点是可累加的,具有原子性,都是一个逻辑计量单元,或者一个时间段内的柱状图。 例如:队列的当前深度可以被定义为一个计量单元,在写入或读取时被更新统计; 输入 HTTP 请求的数量可以被定义为一个计数器,用于简单累加; 请求的执行时间可以被定义为一个柱状图,在指定时间片上更新和统计汇总。
-
日志:其特点是描述一些离散的(不连续的)事件。 例如:应用通过一个滚动的文件输出 debug 或 error 信息,并通过日志收集系统,存储到 Elasticsearch 中; 审批明细信息通过 Kafka,存储到数据库(BigTable)中; 又或者,特定请求的元数据信息,从服务请求中剥离出来,发送给一个异常收集服务,如 NewRelic。
-
追踪:其特点是在单次请求的范围内,处理信息。 任何的数据、元数据信息都被绑定到系统中的单个事务上。 例如:一次调用远程服务的 RPC 执行过程;一次实际的 SQL 查询语句;一次 HTTP 请求的业务性 ID。
在前面的文章中,我们通过 EFK 收集日志,对系统和各个服务的运行状态进行监控;通过 Prometheus 收集指标(Metrics),对系统和各个服务的性能进行监控;通过 Grafana 可视化指标并及时警报。
本篇开始,将为大家带来分布式追踪,以此来完善微服务监控系统。
分布式追踪
分布式追踪可以通过对微服务调用链的跟踪,构建一个从服务请求开始到各个微服务交互的全部调用过程的视图。用户可以从中了解到诸如应用调用的时延,网络调用(HTTP,RPC)的生命周期,系统的性能瓶颈等等信息。
谷歌在 2010 年发表的论文 《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》 中介绍了分布式追踪的概念。
主要概念:
追踪(Trace)
就是由分布的微服务协作所支撑的一个事务。一个追踪,包含为该事务提供服务的各个服务请求。
跨度(Span)
Span 是事务中的一个工作流,一个 Span 包含了时间戳,日志和标签信息。Span 之间包含父子关系,或者主从(Followup)关系。
跨度上下文(Span Context)
跨度上下文是支撑分布式追踪的关键,它可以在调用的服务之间传递,上下文的内容包括诸如:从一个服务传递到另一个服务的时间,追踪的 ID,Span 的 ID 还有其它需要从上游服务传递到下游服务的信息。
OpenTracing
随着分布式追踪的流行,各家都发布了自己的产品和设计,这导致无规范可言。
为了解决这个问题,OpenTracing 基于谷歌提出的概念定义了一个开放的分布式追踪的规范。OpenTracing 通过提供平台无关、厂商无关的 API,为分布式追踪提供统一的概念和数据标准,使得开发人员能够方便的添加(或更换)追踪系统的实现。
注:以下篇幅为 The OpenTracing Semantic Specification 的部分翻译。
数据模型
OpenTracing 中的 Traces 由其 Span 隐式定义。Trace 可被认为是由一组 Span 定义的有向无环图(DAG),在 Span 之间的关系被称为 References。
以下是一个由 8 个 Span 构成的 Trace 的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Causal relationships between Spans in a single Trace
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)
有时用时间轴来显示 Traces 更方便,如下图所示:
1
2
3
4
5
6
7
8
9
10
Temporal relationships between Spans in a single Trace
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
每个 Span 封装了如下状态:
- 操作名称
- 开始时间戳
- 结束时间戳
- 一组零或多个键:值结构的 Span 标签(Tags)。键必须是字符串。值可以是字符串,布尔或数值类型.
- 一组零或多个 Span 日志(Logs),其中每个都是一个键:值映射并与一个时间戳配对。键必须是字符串,值可以是任何类型。 并非所有的 OpenTracing 实现都必须支持每种值类型。
- 一个 SpanContext(见下文)
- 零或多个因果相关的 Span 间的 References (通过那些相关的 Span 的 SpanContext)
每个 SpanContext 封装了如下状态:
- 任何需要跟跨进程 Span 关联的,依赖于 OpenTracing 实现的状态(例如 Trace 和 Span 的 id)
- 键:值结构的跨进程的 Baggage Items
Span 间的 Reference
一个 Span 可引用零或多个因果相关的 SpanContext。OpenTracing 目前定义了两种类型的 Reference: ChildOf 和 FollowsFrom。这两种 Reference 类型都对父子 Span 间的因果关系进行了建模。未来,OpenTracing 可能会为不具因果关系的 Span 提供不同类型的 Reference (例如批量的 Span,卡在队列中的 Span 等)。
ChildOf reference: 一个 Span 可以是另一个 Span 的子 Span。在 ChildOf 引用中,父 Span 在某种程度上取决于子 Span。下列情况会构成 ChildOf 关系:
- 在一个 RPC 中,代表服务端的 Span 可作为 ChildOf 代表客户端的 Span
- 在一个持久化进程中,代表 SQL 插入的 Span 可作为 ChildOf 代表 ORM save 方法的 Span
- 多个并发(可能是分布式)执行任务的 Span 可能分别各自为 Childof 一个合并了多个子 Span 结果的父 Span
下列这些都是有效的具有 ChildOf 关系的时序图
1
2
3
4
5
6
7
8
9
[-Parent Span---------]
[-Child Span----]
[-Parent Span--------------]
[-Child Span A----]
[-Child Span B----]
[-Child Span C----]
[-Child Span D---------------]
[-Child Span E----]
FollowsFrom reference: 有些父 Span 不依赖于任何子 Span 的结果。这种情况下,我们仅认为子 Span 在因果上 FollowsFrom 父 Span。有许多不同的 FollowsFrom 引用子类别,在 OpenTracing 的未来版本中,它们可能会被更正式地区分。
下列这些都是有效的具有 FollowsFrom 关系的时序图
1
2
3
4
5
6
7
8
9
[-Parent Span-] [-Child Span-]
[-Parent Span--]
[-Child Span-]
[-Parent Span-]
[-Child Span-]
接口定义
OpenTracing 规范中有三种相互关联的关键类型 Tracer,Span 和 SpanContext。接下来,我们来看一下各种类型的行为; 简单来说,每种行为分别在编程语言中对应为一个”方法”,尽管实际上可能是一组重载方法。
当我们讨论“可选”参数时,应当清楚,不同的语言有不同的方式来解释这个概念。比如说,在 Go 语言中我们会使用 “functional Options” 这个术语,而在 Java 中我们会使用 builder 模式。
Tracer
Tracer 接口创造 Span 并且能够跨进程地 Inject (序列化)和 Extract (反序列化)。严格来说,它应具有以下能力:
启动一个新的 Span
必要参数
- 操作名称,一个人工可读的字符串,它简洁地表示由 Span 完成的工作 (例如,RPC 方法名称、函数名称或一个较大的计算任务中的阶段的名称)。操作名称应该用泛化的字符串形式标识出一个 Span 实例. 也就是说,
get_user比get_user/314159好。
比如说这里有几个操作名称,用于得到一个虚构的账户信息:
| 操作名称 | 建议 |
|---|---|
get |
太宽泛 |
get_account/792 |
太具体 |
get_account |
刚刚好, account_id=792 可作为一个合适的 Span tag |
可选参数
- 零或多个与
SpanContext相关的references,尽可能包括ChildOf和FollowFrom引用类型的信息 - 开始时间戳,如果没有的话,默认使用现实时间(walltime)
- 零或多个标签
返回值是一个刚刚启动的 Span 实例
注入(Inject) SpanContext 到载体中
必要参数
SpanContext实例- 格式描述符(format descriptor)(通常但不一定是字符串常量),告诉 Tracer 的实现如何在载体对象中对 SpanContext 进行编码
- 载体(carrier),其类型由格式描述符指定。
Tracer的实现将根据格式描述对此载体对象中的SpanContext进行编码
从载体中抽取(Extract) SpanContext
必要参数
- 格式描述符(format descriptor),告诉
Tracer的实现如何在载体对象中对SpanContext进行解码 - 载体,其类型由格式描述符指定。
Tracer的实现将根据格式描述对此载体对象中的SpanContext进行解码
返回值是一个 SpanContext 实例,适合作为通过 Tracer 启动 Span 时的 reference
注意: Injection 和 Extraction 所需的格式
Injection 和 Extraction 都依赖于一个可扩展的格式描述符参数,其指定了相关联的”载体”类型以及 SpanContext 是如何被编码的。Tracer 实现必须支持下列所有格式。
- 文本映射(Text Map): 任意的无字符编码限制的 string-string 型键值结构
- HTTP Headers: string-string 型的键值结构在 HTTP headers(RFC 7230)中也适用。在实操中,由于 HTTP header 很容易被各种不同的方式处理, 强烈建议在 Tracer 的实现中使用有限的键空间和保守的转意值
- 二进制: 代表了
SpanContext的任意二进制数据
Span
除了获取 Span 的 SpanContext 的方法之外,下面任何方法都不能在 Span 完成后被调用。
获取 Span 的 SpanContext
无需参数。
返回值是 Span 的 SpanContext 。返回值甚至可能在 Span 结束后被使用。
重写操作名
必要参数
- 新的操作名,当 Span 启动时取代旧内容
结束 Span
可选参数
显式地添加 Span 的结束时间戳,如果没有这个参数则会隐式的添加现实时间(walltime) 除了获取 Span 的 SpanContext 的方法之外,任何 Span 对象的方法都不能在其完成后被调用。
设置 Span 标签
必要参数
- 标签的键,必须是字符串
- 标签的值,必须是字符串,布尔值,数值类型其中之一
注意 OpenTracing 项目文档中已经为一些“标准标签”规定了语义。
记录(Log) 结构化的数据
必要参数
- 一到多个键值对,键必须是字符串,值可以是任意类型。有些 OpenTracing 的实现可以处理更多的日志的值。
可选参数
- 显式时间戳。该参数必须落在当前 Span 的开始与结束时间戳之间。
注意 OpenTracing 项目文档中已经为一些“日志的标准键”规定了语义。
设置(set) baggage item
Baggage item 是对应于某个 Span 及其 SpanContext ,以及所有直接或间接引用自本地(local) Span 的 Span 的键值对。也就是说,baggage items 是与其 trace 一起传播的。
Baggage item 为全栈式的 OpenTracing 集成提供了强大的功能(比如在移动 App 上使用时,它可以一路追踪数据直至储存系统的深度),不过使用这些功能时要当心。
每个键值都会被拷贝到每一个本地(local)及远程的子 Span,这可能导致巨大的网络和 CPU 开销。
必要参数
- baggage 键,字符串
- baggage 值,字符串
获取(get) baggage item
必要参数
- baggage 键,字符串
返回值是对应的 baggage 值,或是一个表示没有 baggage 值的一个量。
SpanContext
在一般所指的 OpenTracing 层面上,SpanContext 更像是一个概念而不是一种实用功能。也就是说,这对 OpenTracing 的实现来说提供一层薄的接口是至关重要的。当启动一个 Span 或者注入/提取(injecting/extracting) trace 时,多数 OpenTracing 用户仅通过 reference 与 SpanContext 进行交互。
在 OpenTracing 中,SpanContext 被强制设定为不可变的(immutable),以应对在 Span 结束时和引用(reference)时产生的复杂的生命周期问题。
遍历所有的 baggage item
不同语言对此有不同的建模方式,不过给出一个 SpanContext 实例,语义上还是应该能让调用者在短时间内遍历 baggage items。
NoopTracer
所有语言的 OpenTracing API 必须提供某种 NoopTracer 实现,可用作标记控制(flag-control)或者进行一些用于测试的无害注入等。某些情况下(比如 Java),NoopTracer 可能在它自己的制品包(packaging artifact)中。
可选的 API 元素
有些语言提供了在单进程中用来传递活动的 Span 和 SpanContext 的工具。比如,opentracing-go 提供了在 Go 的 context.Context 机制中,用来 set 和 get 活动 Span 的帮助函数(helpers)。
小结
本篇文章作为分布式追踪 的开篇,为大家介绍了分布式追踪的概念和作用,以及 OpenTracing 的出现和术语。希望能帮助大家对分布式追踪有个概念,下一篇将为大家介绍 CNCF 的分布式追踪方案 Jaeger。
 SwiftUI - 获取子视图信息(大小、标题等)
SwiftUI - 获取子视图信息(大小、标题等)