前面几篇文章我们使用 Prometheus 采集了各种各样的监控数据指标,并使用 promQL 语句查询出了一些数据,在 Prometheus 的 Dashboard 中进行了展示,但是明显可以感觉到 Prometheus 的图表功能相对较弱,所以一般情况下我们会一个第三方的工具来展示这些数据,也就是本篇文章要介绍的 Grafana。
简介
![]()
Grafana 是一个跨平台的度量分析和可视化工具,可以通过将采集的数据查询和可视化展示,并及时警报。
Grafana 具有可插拔数据源模型,支持许多流行的时间序列数据库,如 Graphite,Prometheus,Elasticsearch,OpenTSDB 和 InfluxDB。
特性
可以前往 https://play.grafana.org 体验 Grafana 特性。
可视化
快速灵活的可视化以及多种选择,使你可以以任何方式可视化数据。官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式。
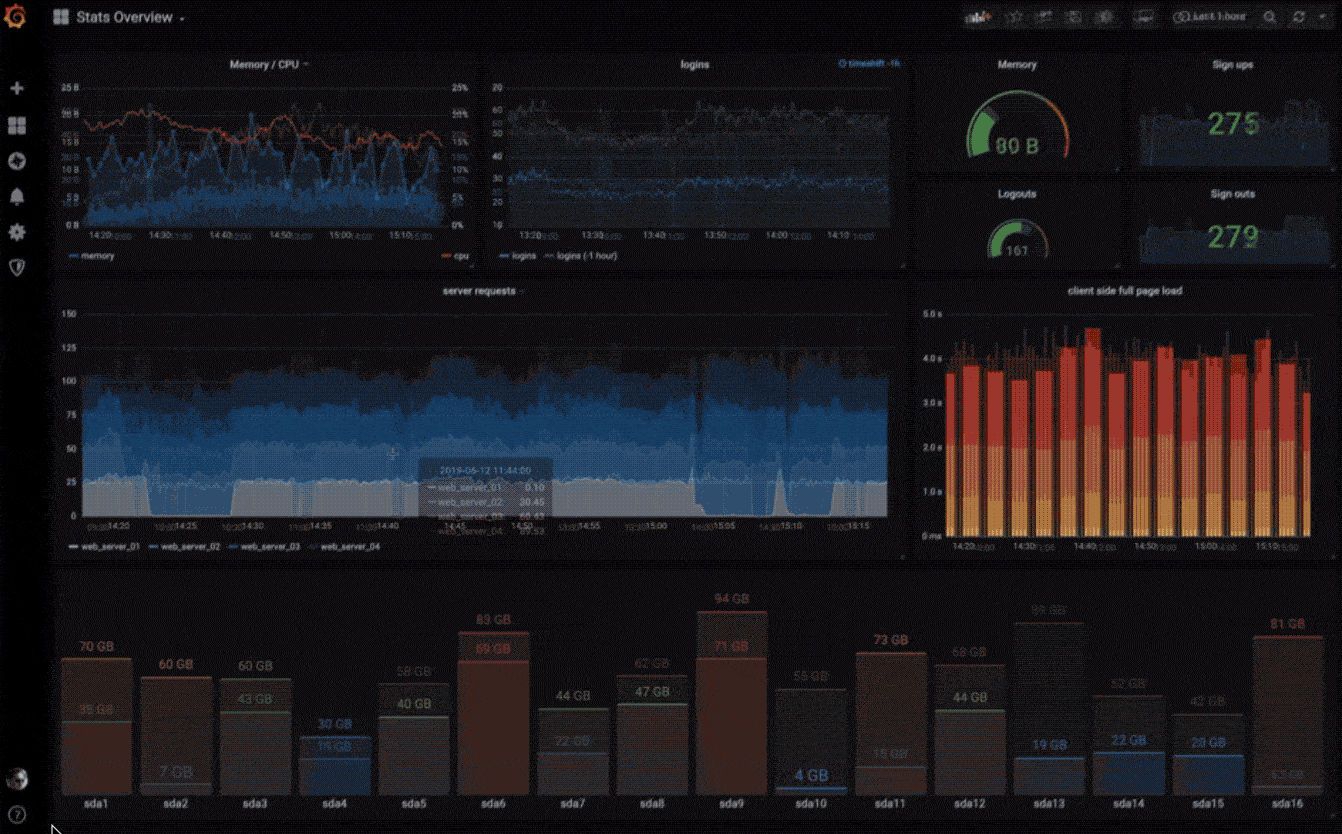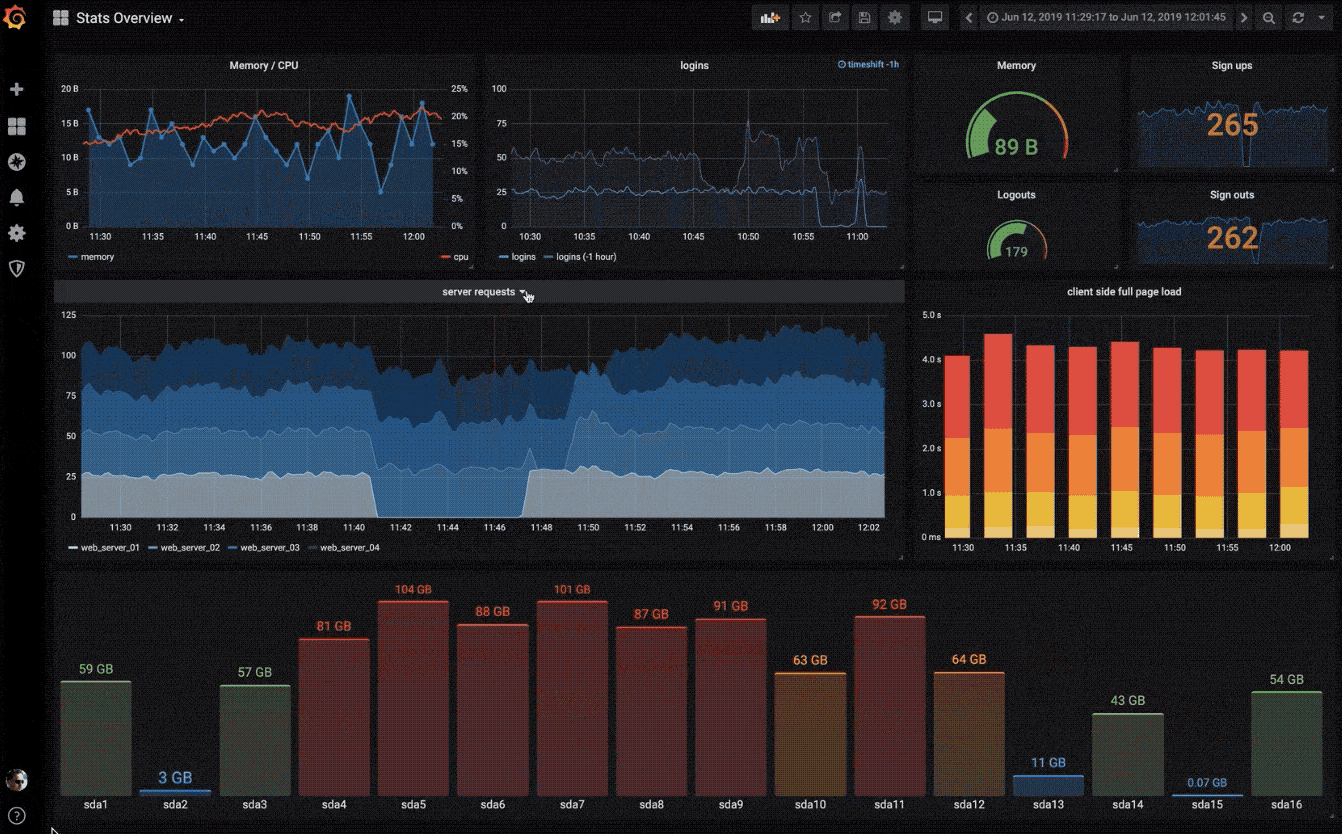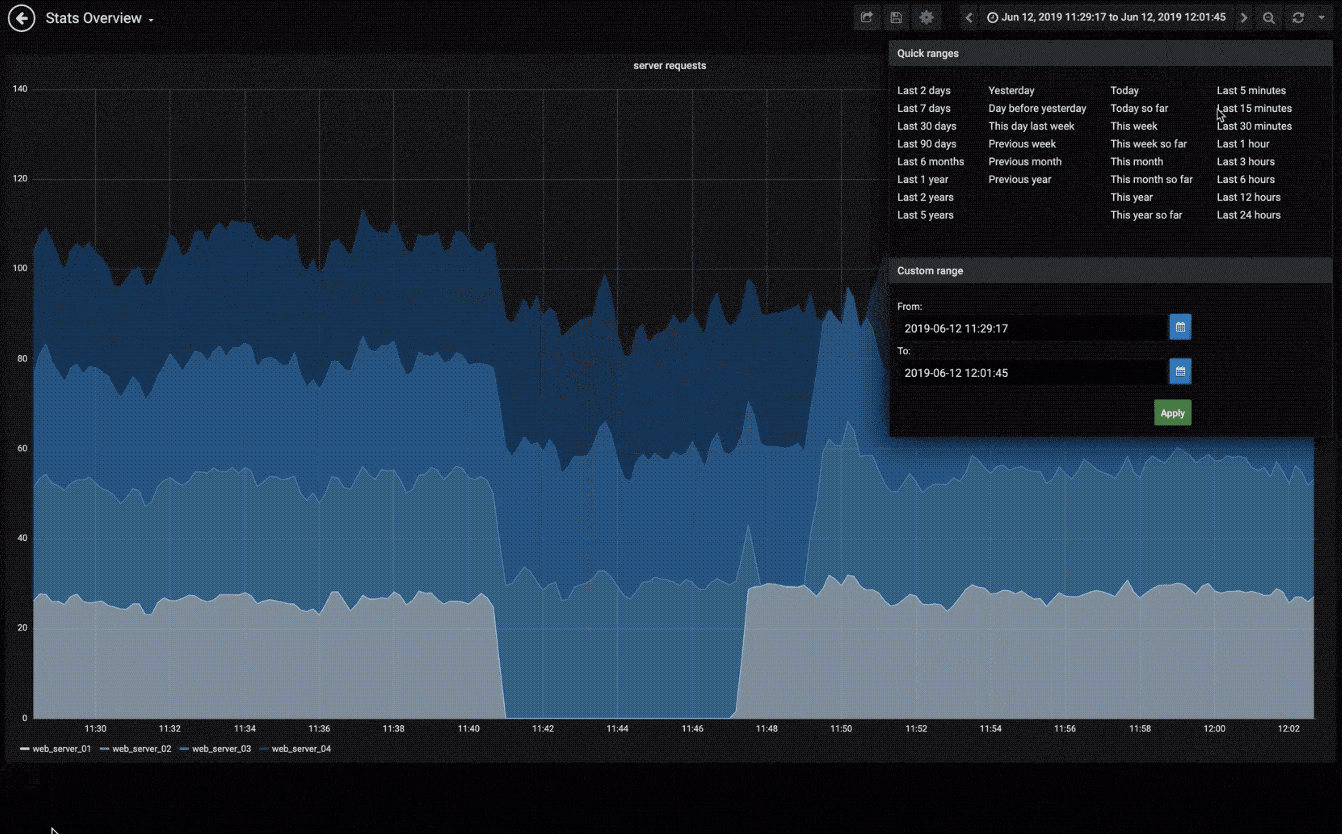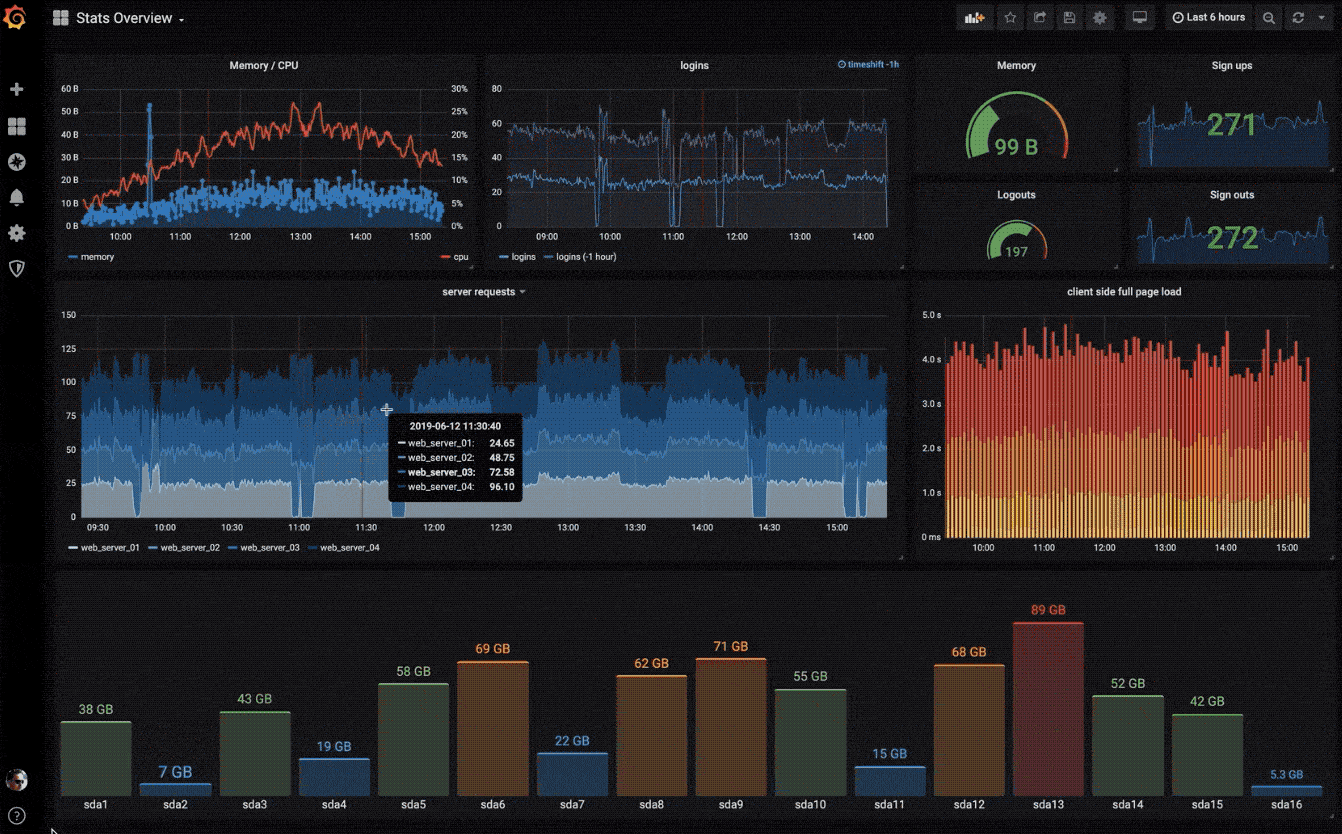
动态仪表盘
使用模板变量创建动态且可重复使用的仪表板,这些模板变量显示在仪表板顶部。
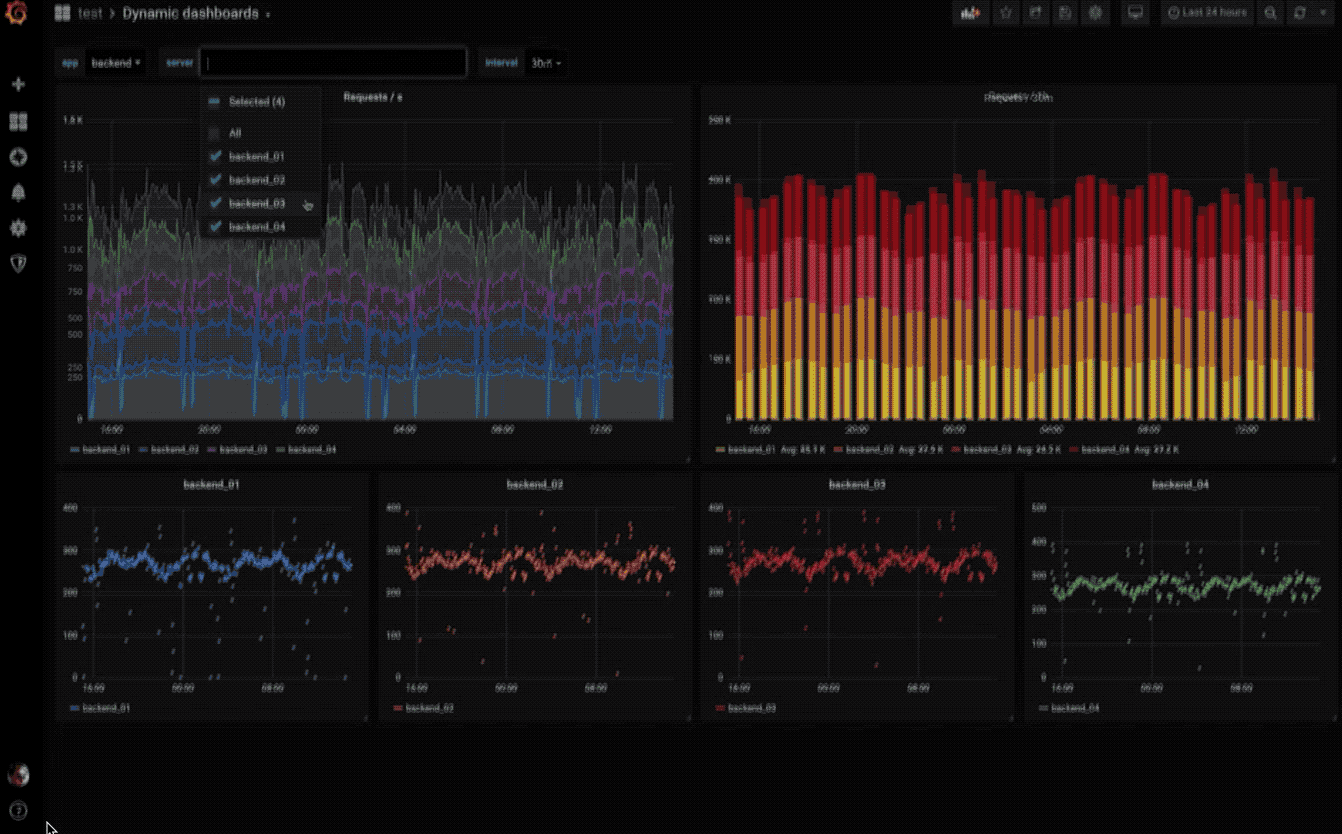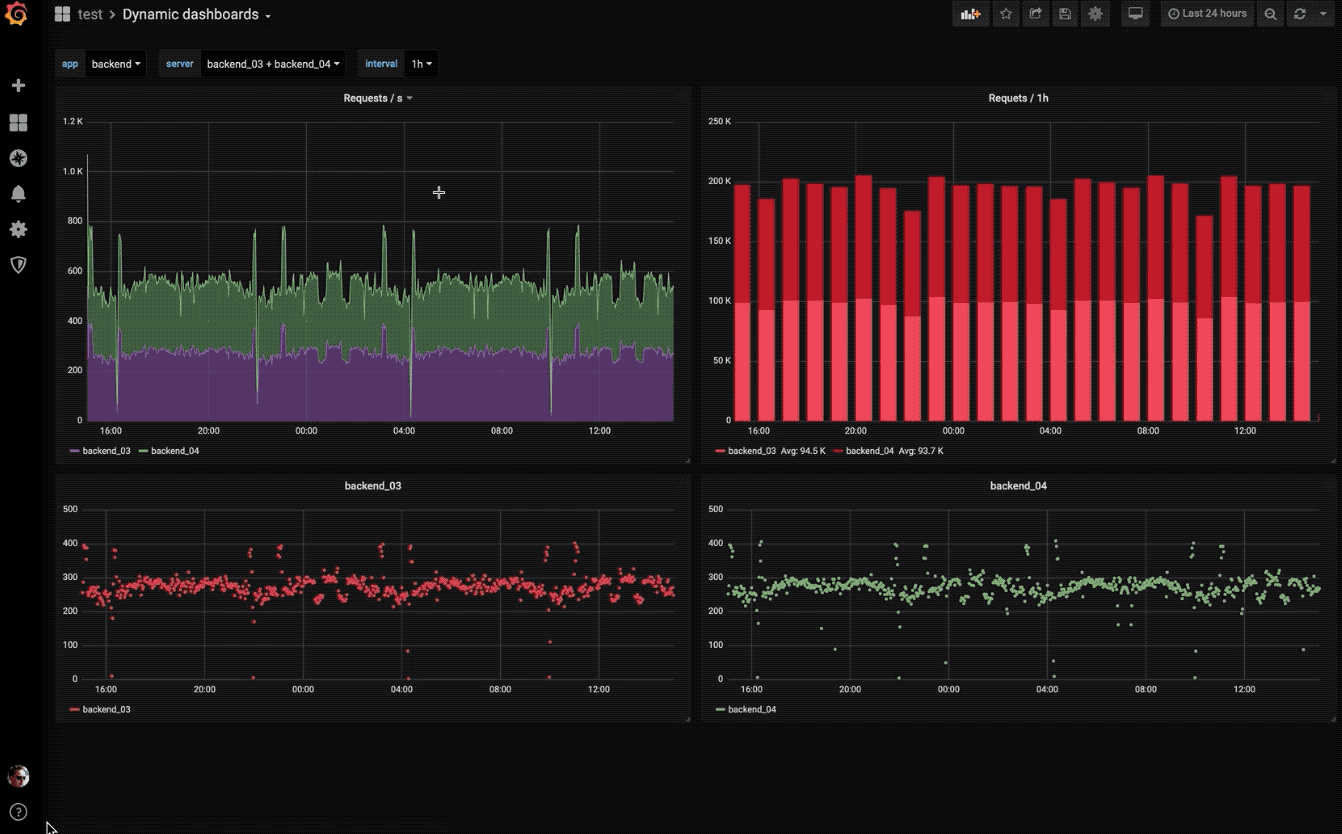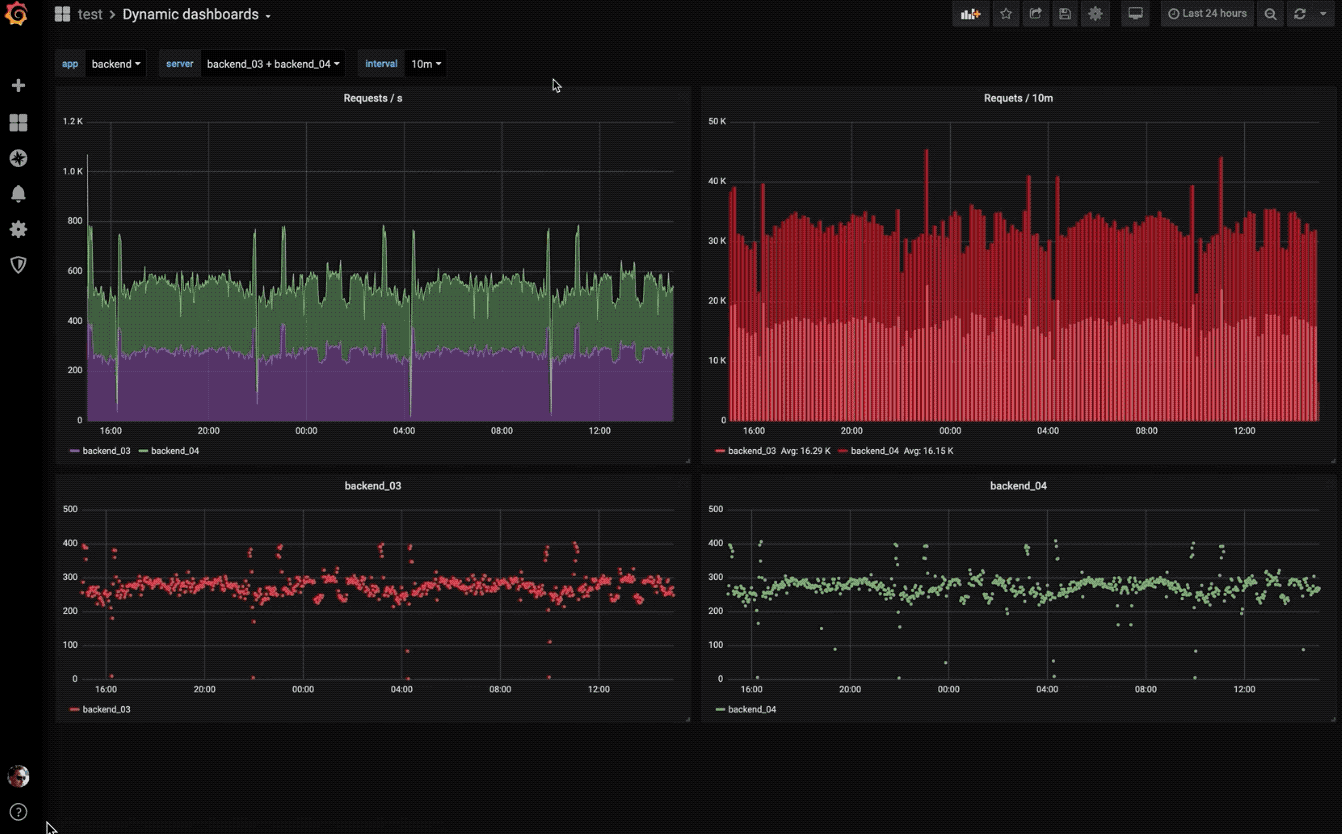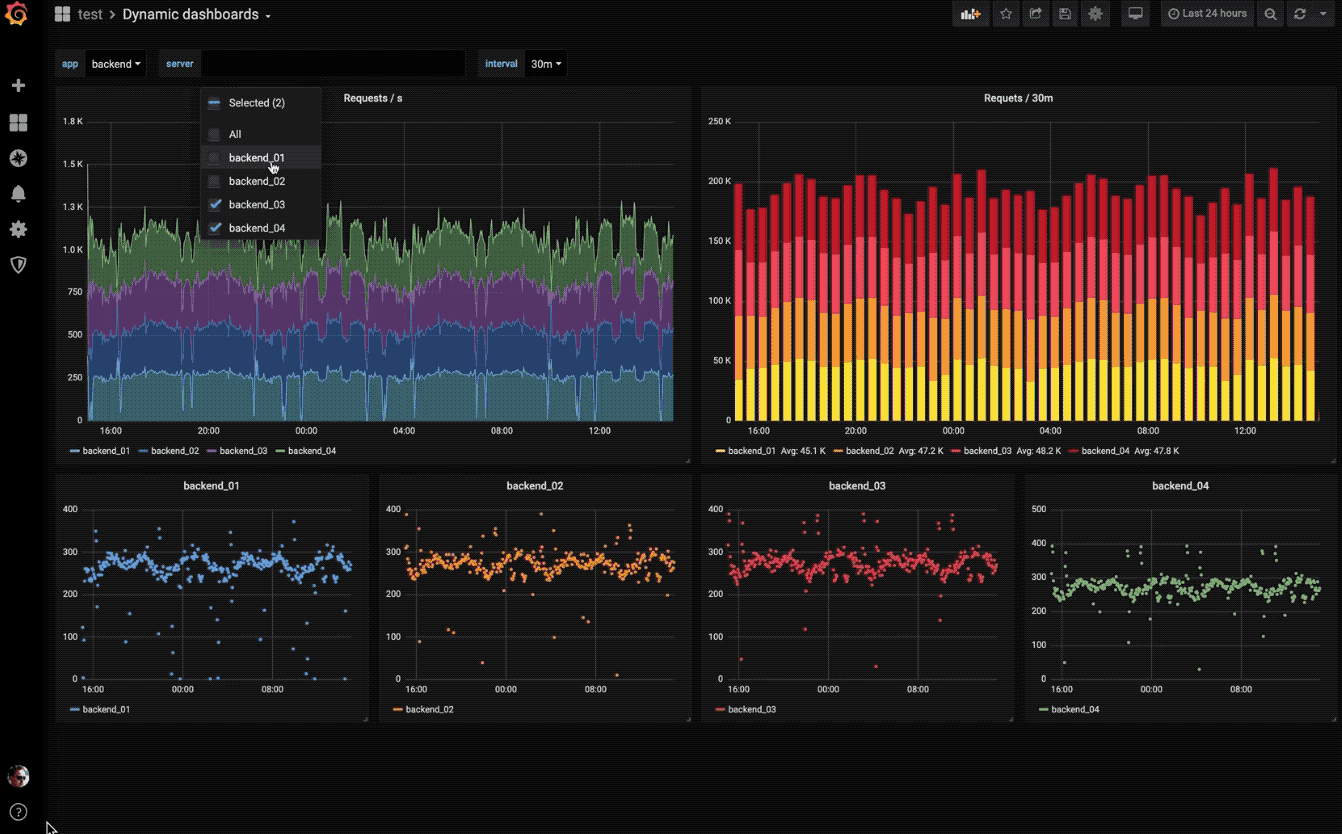
探索指标
通过临时查询和动态明细浏览数据。拆分视图并排比较不同的时间范围,查询和数据源。

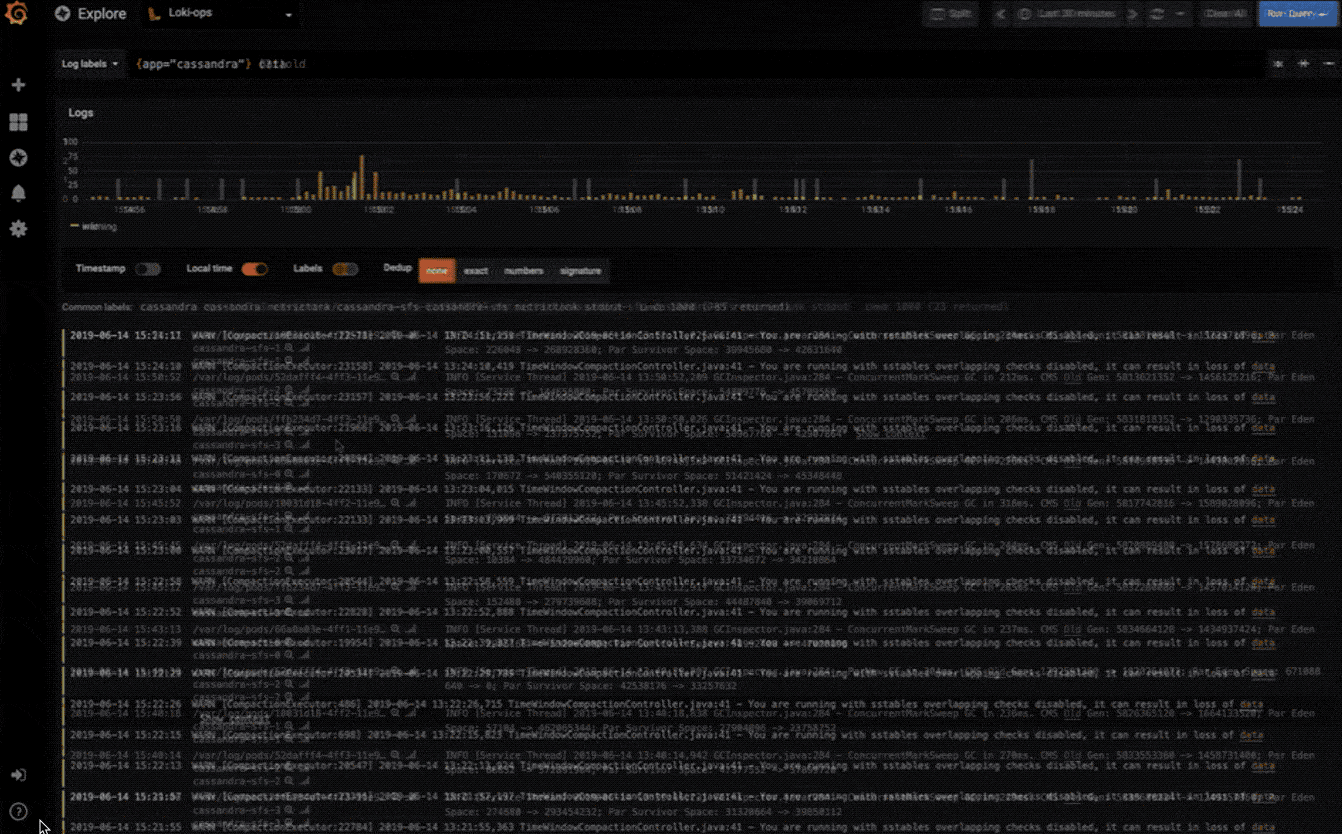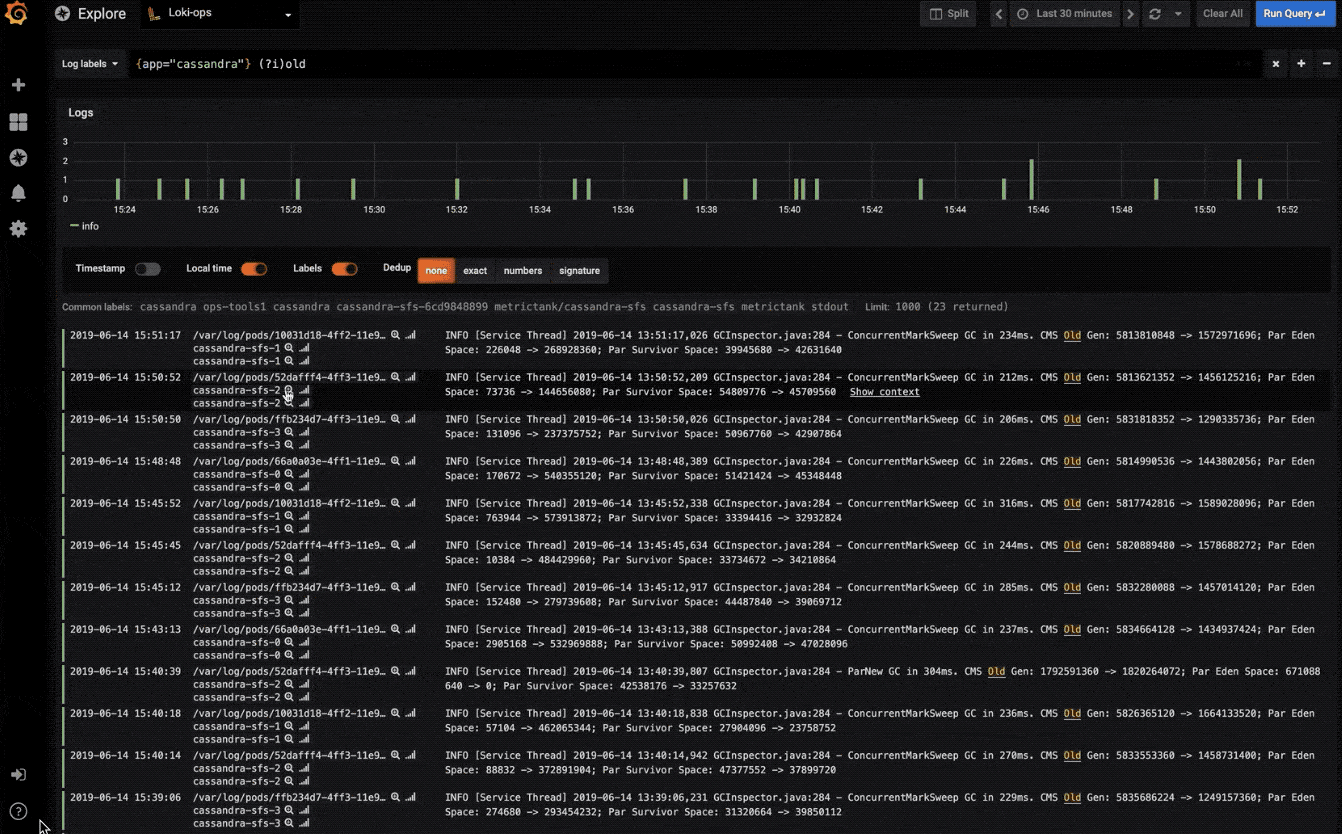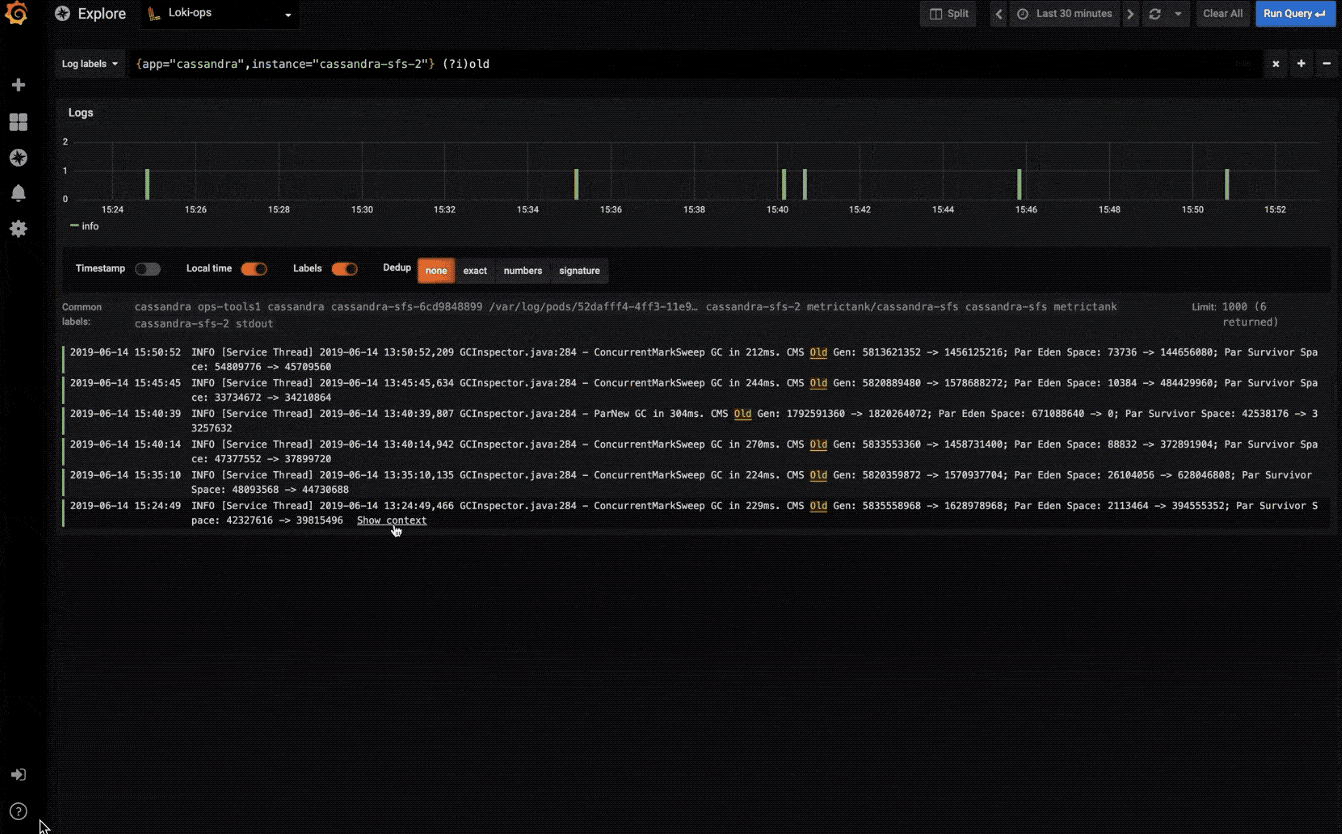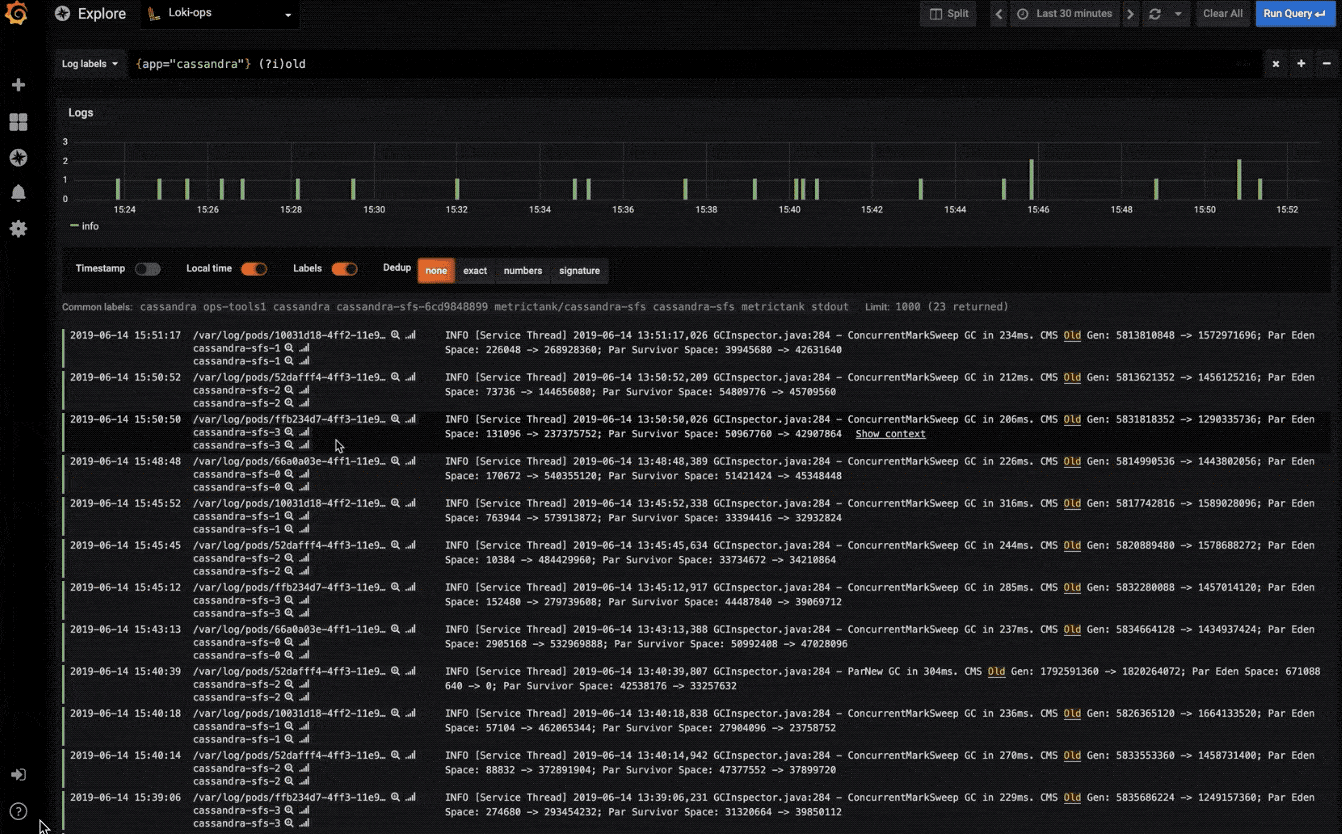
探索日志
快速搜索所有日志或实时流式传输(与 Loki 数据源配合使用效果最佳)。
警报
以可视方式定义最重要指标的警报规则。Grafana 将不断评估并向 Slack,PagerDuty,VictorOps 和 OpsGenie 等系统发送通知。

混合数据源
在同一张图中混合使用不同的数据源!你可以为每个查询指定数据源(适用于自定义数据源)。
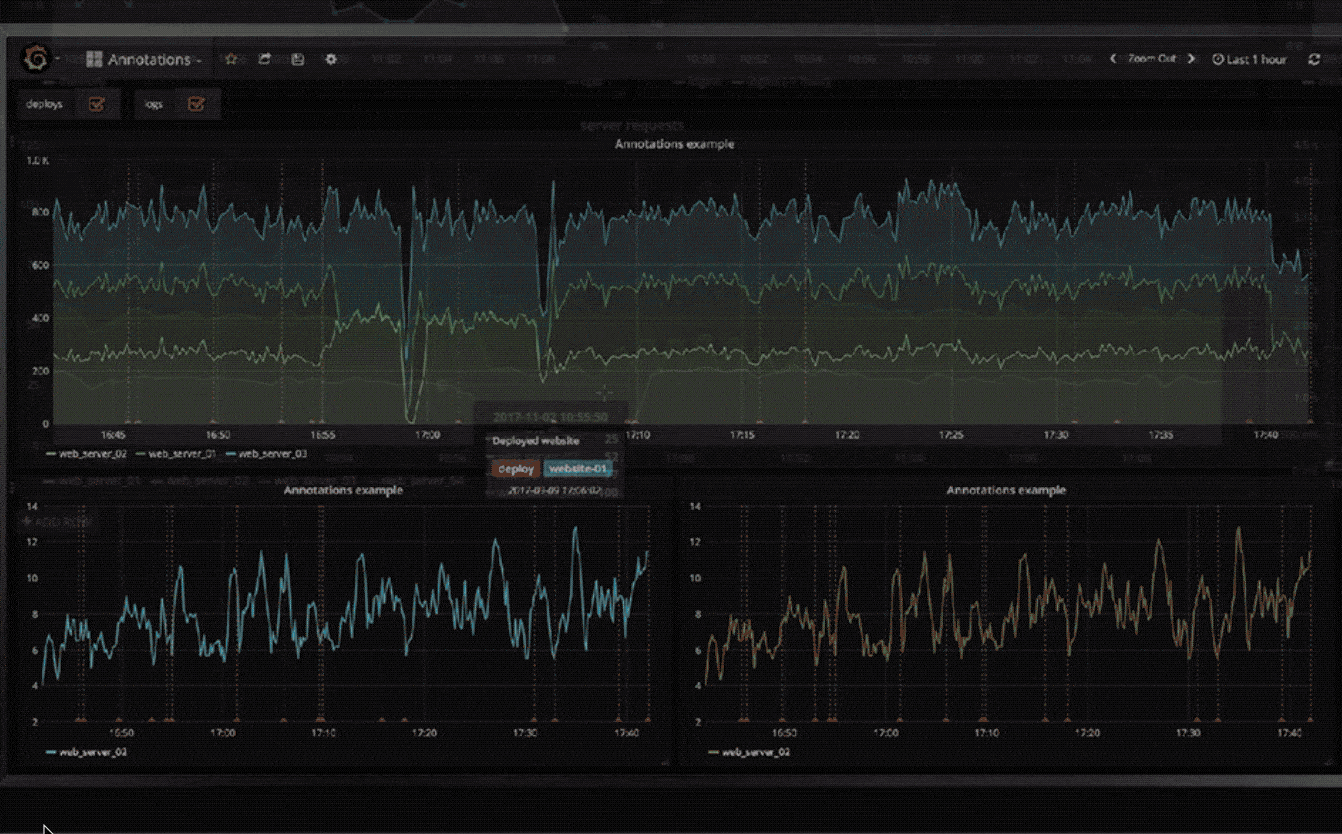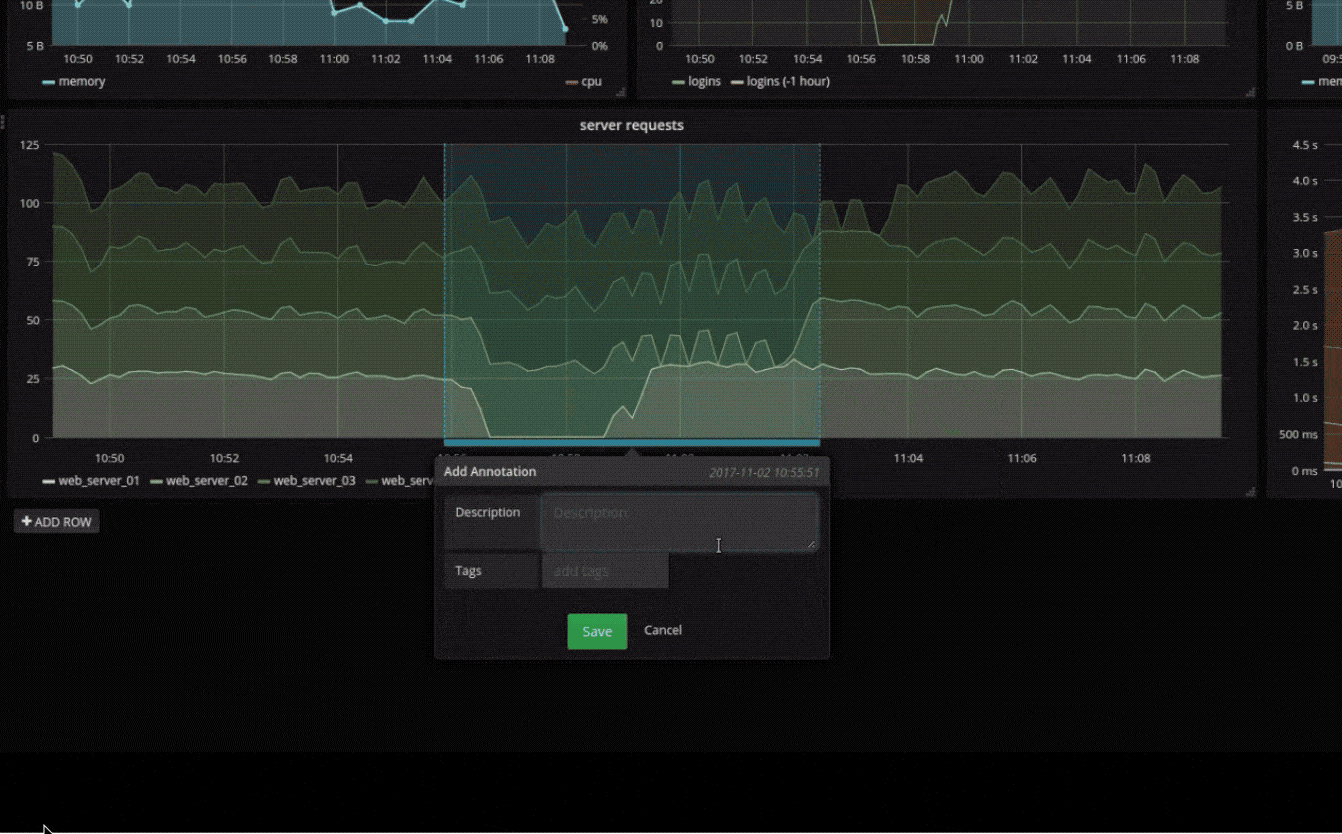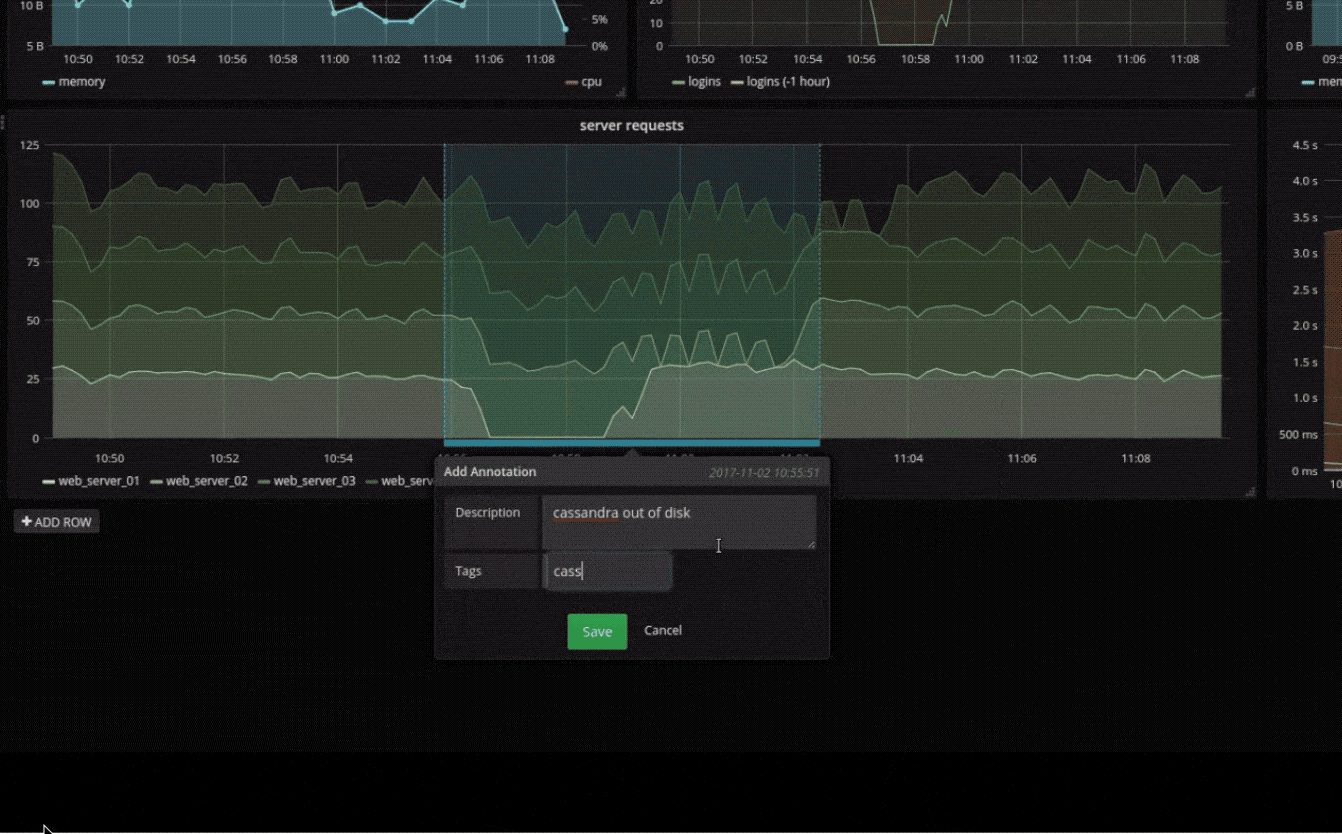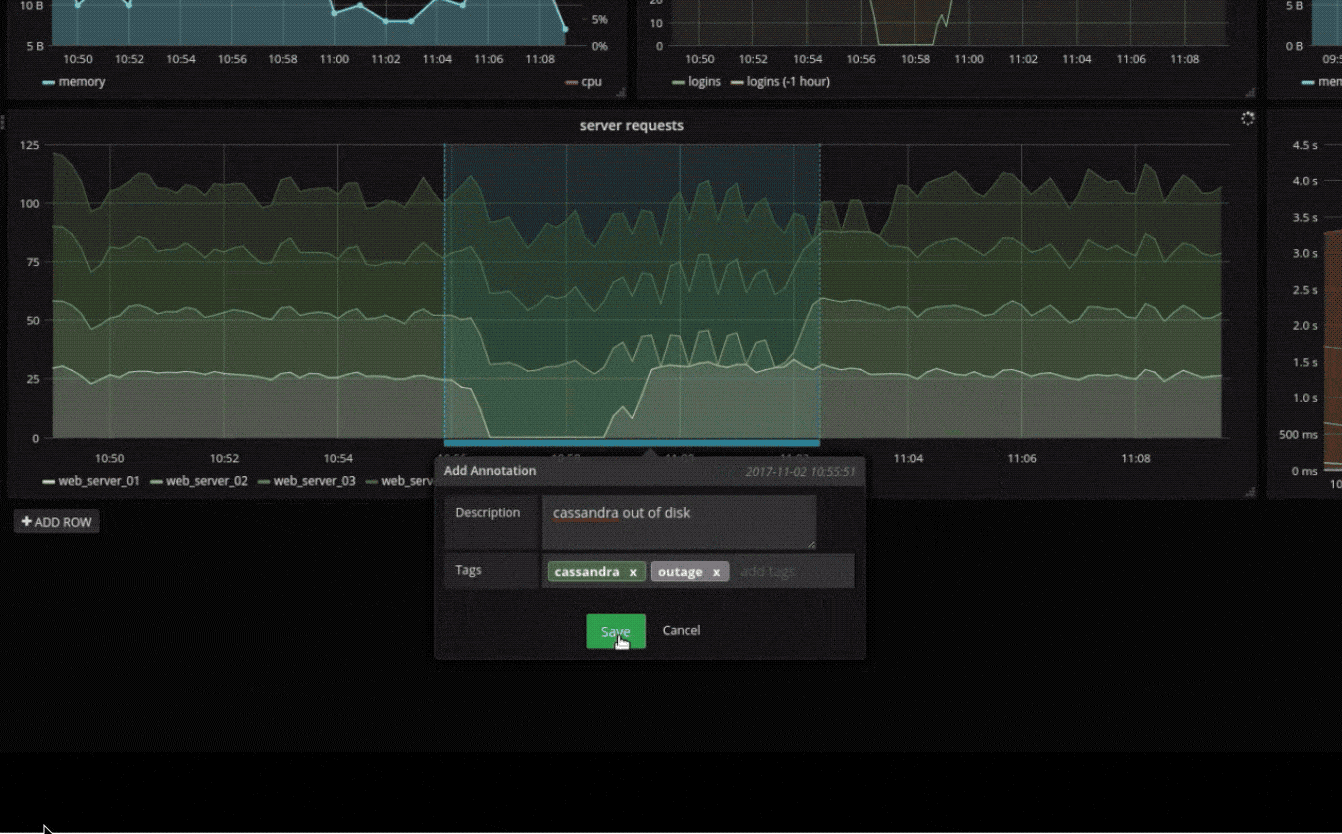
注解
使用来自不同数据源的丰富事件注释图形。将鼠标悬停在事件上会显示完整的事件元数据和标签。
临时过滤器
临时过滤器允许您即时创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
安装
部署文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana
namespace: observability
labels:
app.kubernetes.io/name: grafana
app.kubernetes.io/instance: grafana
app.kubernetes.io/version: "7.0.5"
data:
grafana.ini: |
[analytics]
check_for_updates = true
[grafana_net]
url = https://grafana.net
[log]
mode = console
[paths]
data = /var/lib/grafana/data
logs = /var/log/grafana
plugins = /var/lib/grafana/plugins
provisioning = /etc/grafana/provisioning
datasources.yaml: |
apiVersion: 1
datasources:
- access: proxy
editable: true
isDefault: true
jsonData:
timeInterval: 5s
name: Prometheus
orgId: 1
type: prometheus
url: http://prometheus:9090
注:
- url: http://prometheus:9090 指定了 Prometheus 数据源地址,因为在同一个命名空间下,所以直接使用 service 名称访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# service.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: observability
labels:
app.kubernetes.io/name: grafana
app.kubernetes.io/instance: grafana
app.kubernetes.io/version: "7.0.5"
spec:
type: NodePort
ports:
- name: service
port: 3000
protocol: TCP
selector:
app.kubernetes.io/name: grafana
app.kubernetes.io/instance: grafana
注:
- type: NodePort 为了在开发环境中方便访问,这里使用 NodePort 暴露服务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: observability
labels:
app.kubernetes.io/name: grafana
app.kubernetes.io/instance: grafana
app.kubernetes.io/version: "7.0.5"
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: grafana
app.kubernetes.io/instance: grafana
strategy:
type: RollingUpdate
template:
metadata:
labels:
app.kubernetes.io/name: grafana
app.kubernetes.io/instance: grafana
app: grafana
spec:
securityContext:
fsGroup: 472
runAsGroup: 472
runAsUser: 472
containers:
- name: grafana
image: "grafana/grafana:7.0.5"
imagePullPolicy: IfNotPresent
volumeMounts:
- name: config
mountPath: "/etc/grafana/grafana.ini"
subPath: grafana.ini
- name: storage
mountPath: "/var/lib/grafana"
- name: config
mountPath: "/etc/grafana/provisioning/datasources/datasources.yaml"
subPath: datasources.yaml
ports:
- name: service
containerPort: 3000
protocol: TCP
- name: grafana
containerPort: 3000
protocol: TCP
env:
- name: "GF_SECURITY_ADMIN_PASSWORD"
value: "admin123"
- name: "GF_SECURITY_ADMIN_USER"
value: "admin"
livenessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
initialDelaySeconds: 60
timeoutSeconds: 30
readinessProbe:
httpGet:
path: /api/health
port: 3000
resources: {}
volumes:
- name: config
configMap:
name: grafana
- name: storage
emptyDir: {}
注:
- GF_SECURITY_ADMIN_USER 用户名
- GF_SECURITY_ADMIN_PASSWORD 密码
部署
1
2
3
4
5
6
$ kubectl apply -f config.yaml
configmap/grafana created
$ kubectl apply -f deployment.yaml
deployment.apps/grafana created
$ kubectl apply -f service.yaml
service/grafana created
检查
1
2
3
4
5
6
7
8
9
10
11
12
13
$ kubectl get deployment -n observability
NAME READY UP-TO-DATE AVAILABLE AGE
grafana 1/1 1 1 4m6s
httpbin 1/1 1 1 2d5h
prometheus 1/1 1 1 6d4h
redis 1/1 1 1 2d6h
$ kubectl get service -n observability
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.96.124.67 <none> 3000:31273/TCP 4m10s
httpbin ClusterIP 10.111.188.30 <none> 8000/TCP 2d5h
node-exporter NodePort 10.111.82.119 <none> 9100:31672/TCP 3d5h
prometheus NodePort 10.98.133.13 <none> 9090:31033/TCP 6d4h
redis ClusterIP 10.104.118.216 <none> 6379/TCP,9121/TCP 2d6h
访问
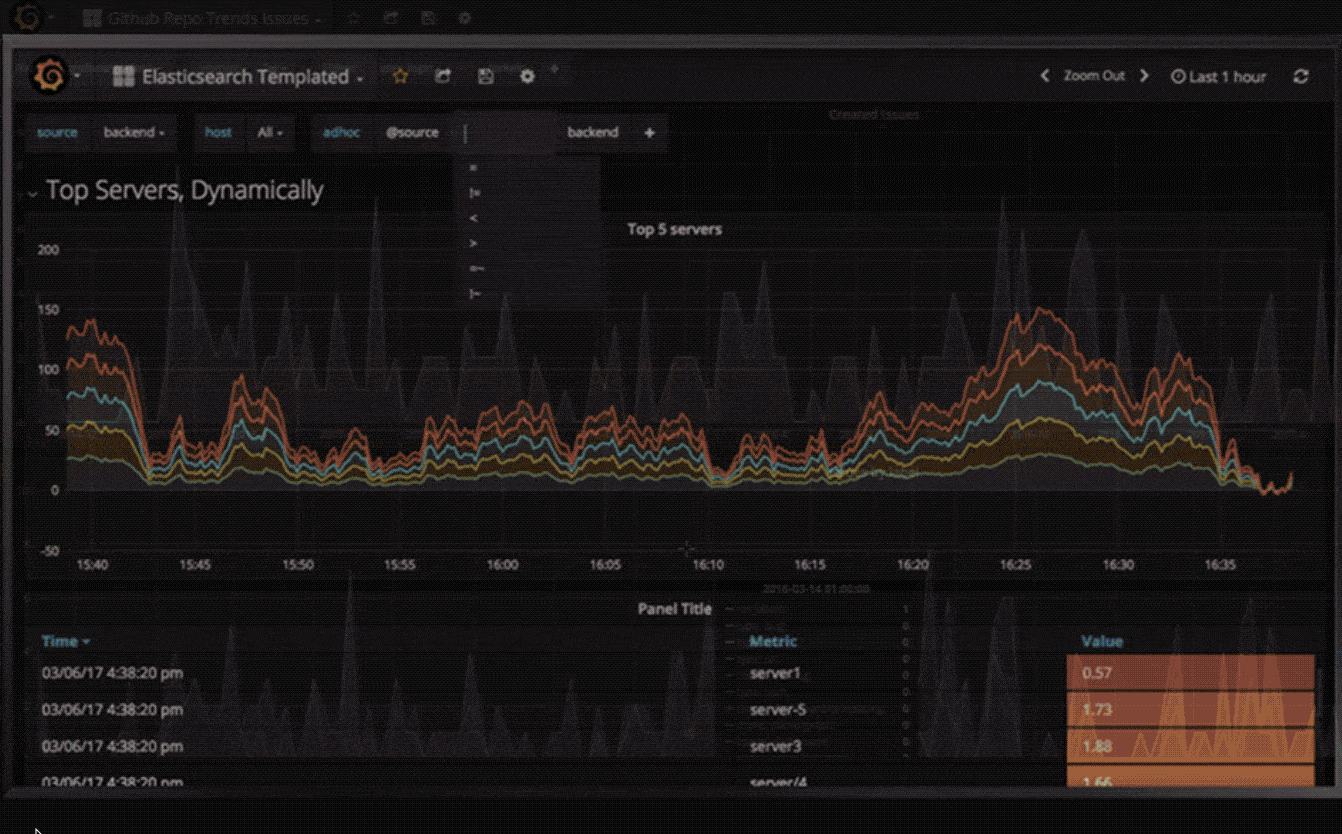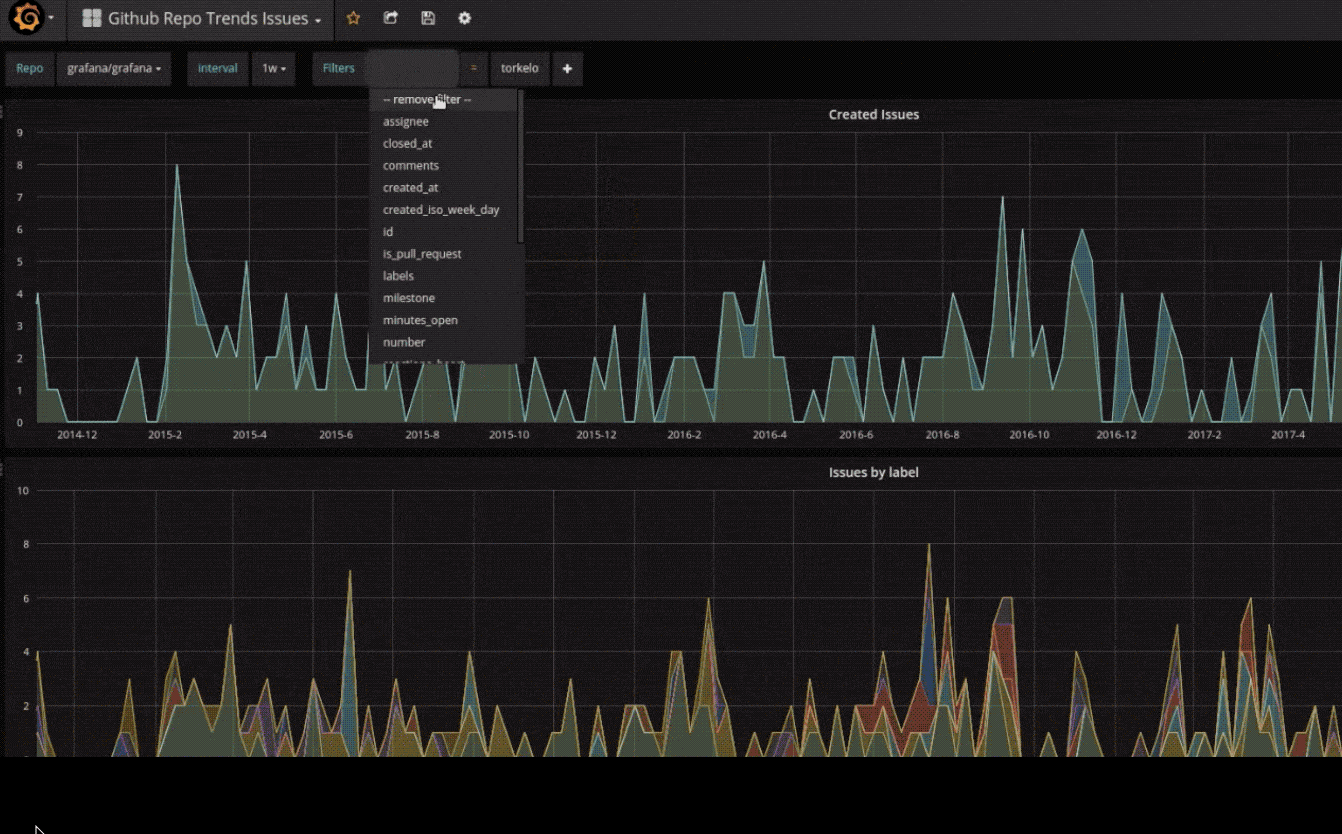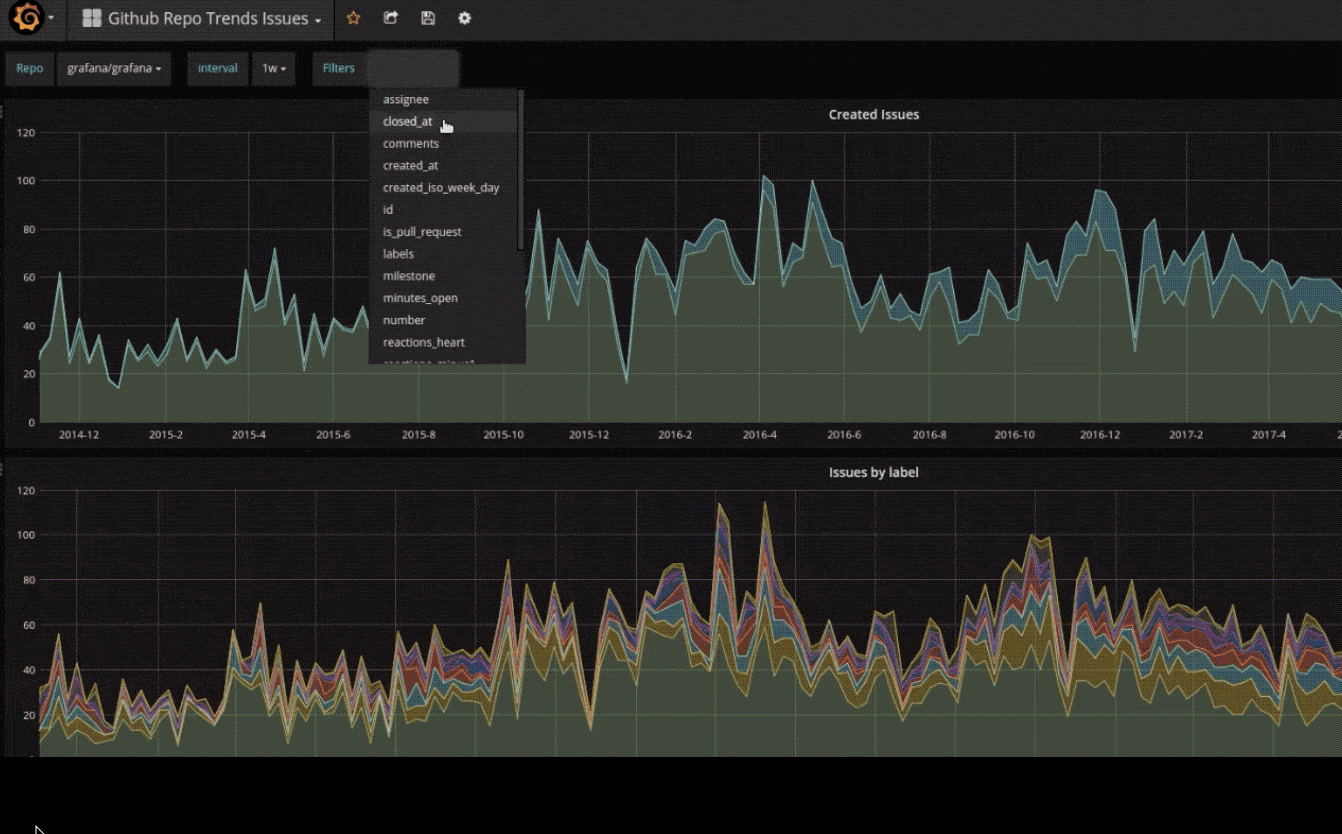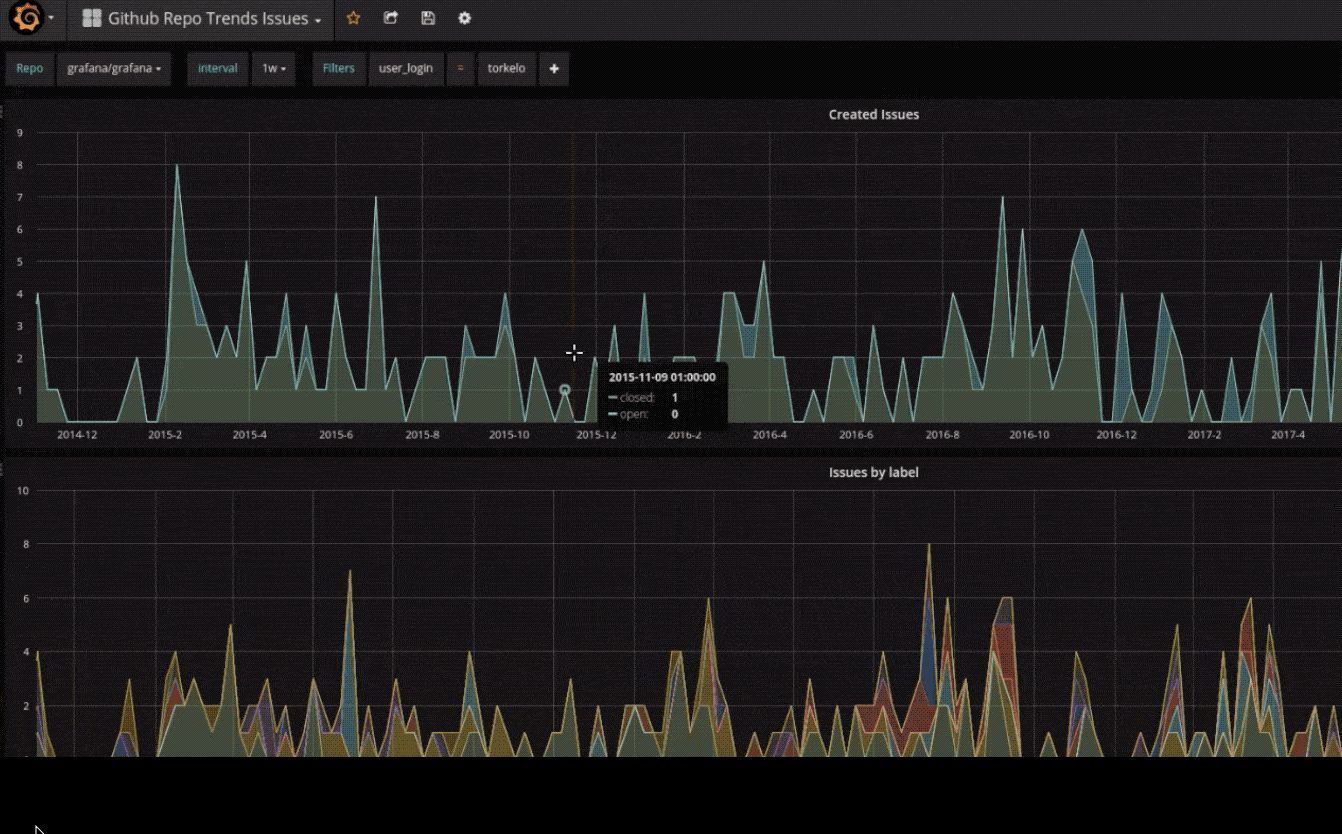
根据服务端口访问 Grafana http://localhost:31273,并使用设置的用户名和密码登录。
Dashboard
导入 Dashboard
为了观察指标,我们可以根据自己的需求手动新建一个 Dashboard。除此之外,grafana 官网上还有很多公共的 Dashboard 可以选用。
由于在监控 Kubernetes 集群中我们讲解过使用 node_exporter 采集服务器节点的运行指标,所以下面以 Node Exporter for Prometheus Dashboard 为例讲解如何导入公共的 Dashboard。
点击 Import
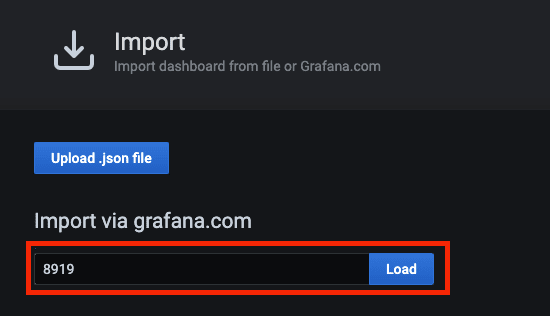
输入Node Exporter for Prometheus Dashboard 的 id,并点击 Load
选择数据源并点击 Import 导入

查看 Dashboard
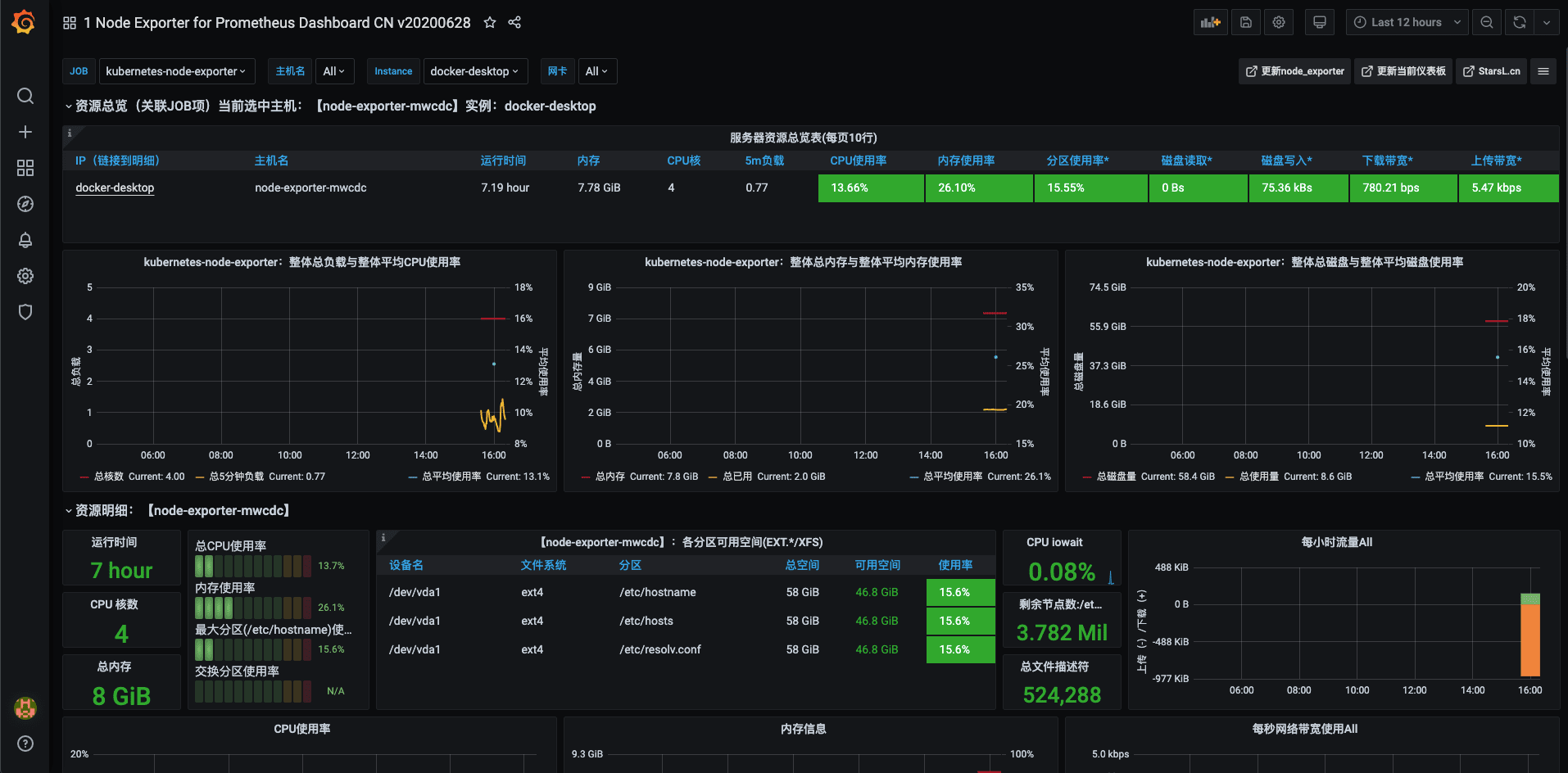
指标可视化流程
选择某个图表,右键选择 Edit
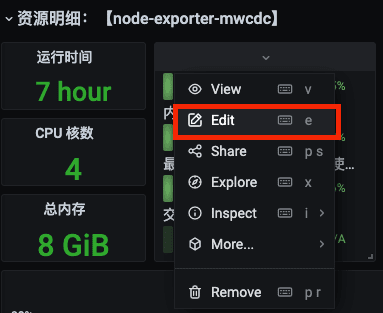
可以看到图表显示的值,其实是将指标通过计算而来的。
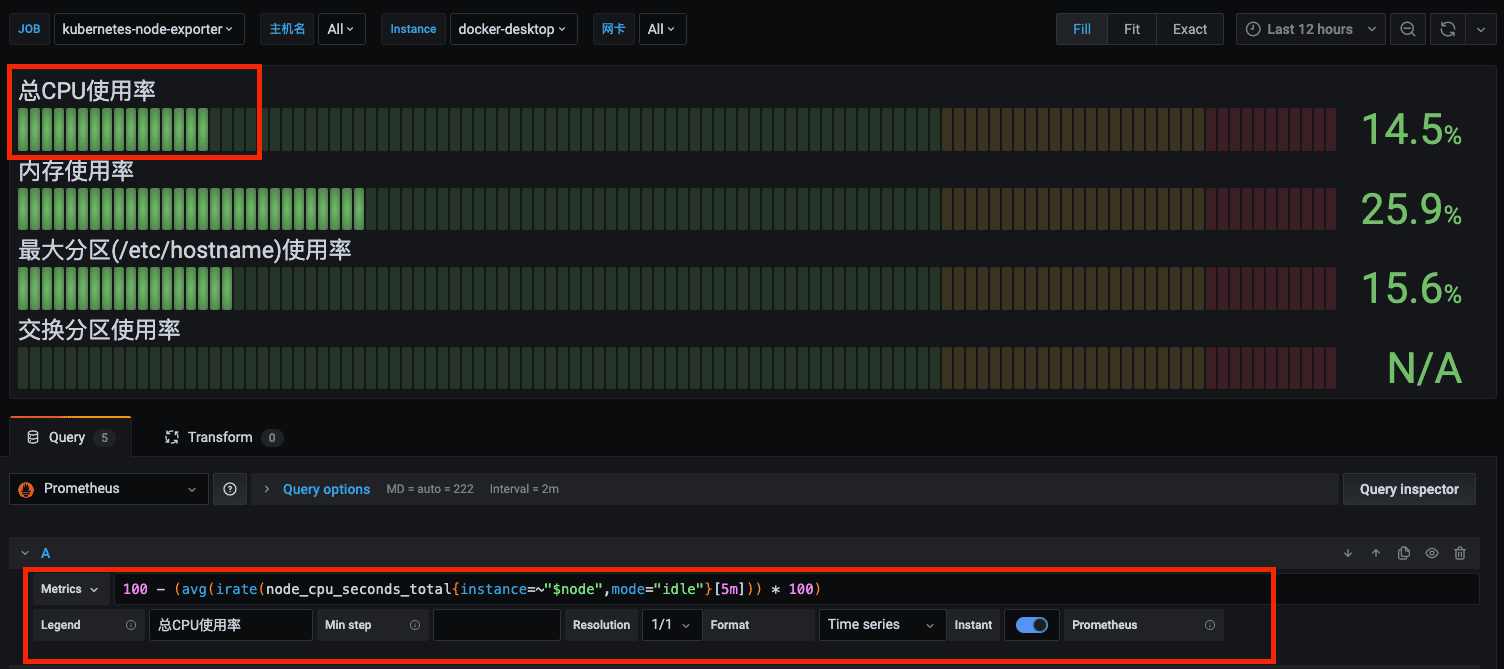
如上图,总 CPU 使用率是通过 100 - (avg(irate(node_cpu_seconds_total{instance=~"$node",mode="idle"}[5m])) * 100) 计算得出的结果。而 node_cpu_seconds_total 便是使用 node_exporter 采集到的服务器节点指标中的一个。
所以,指标可视化流程是,先配置 Prometheus 采集想要的指标,然后使用 promQL 语句查询出想要的数据,最后通过 Grafana 可视化。
如果grafana 官网的 Dashboard 不能满足要求,也可以新建一个自定义 Dashboard,具体的 promQL 语句参考导入的 Dashboard 即可,这里不再赘述。
报警
报警是监控系统中必不可少的环节,grafana 支持很多种形式的报警功能,比如 email、钉钉、slack、webhook 等等,下面我们以钉钉为例。
钉钉
设置报警前,需要设置下钉钉通知参数。
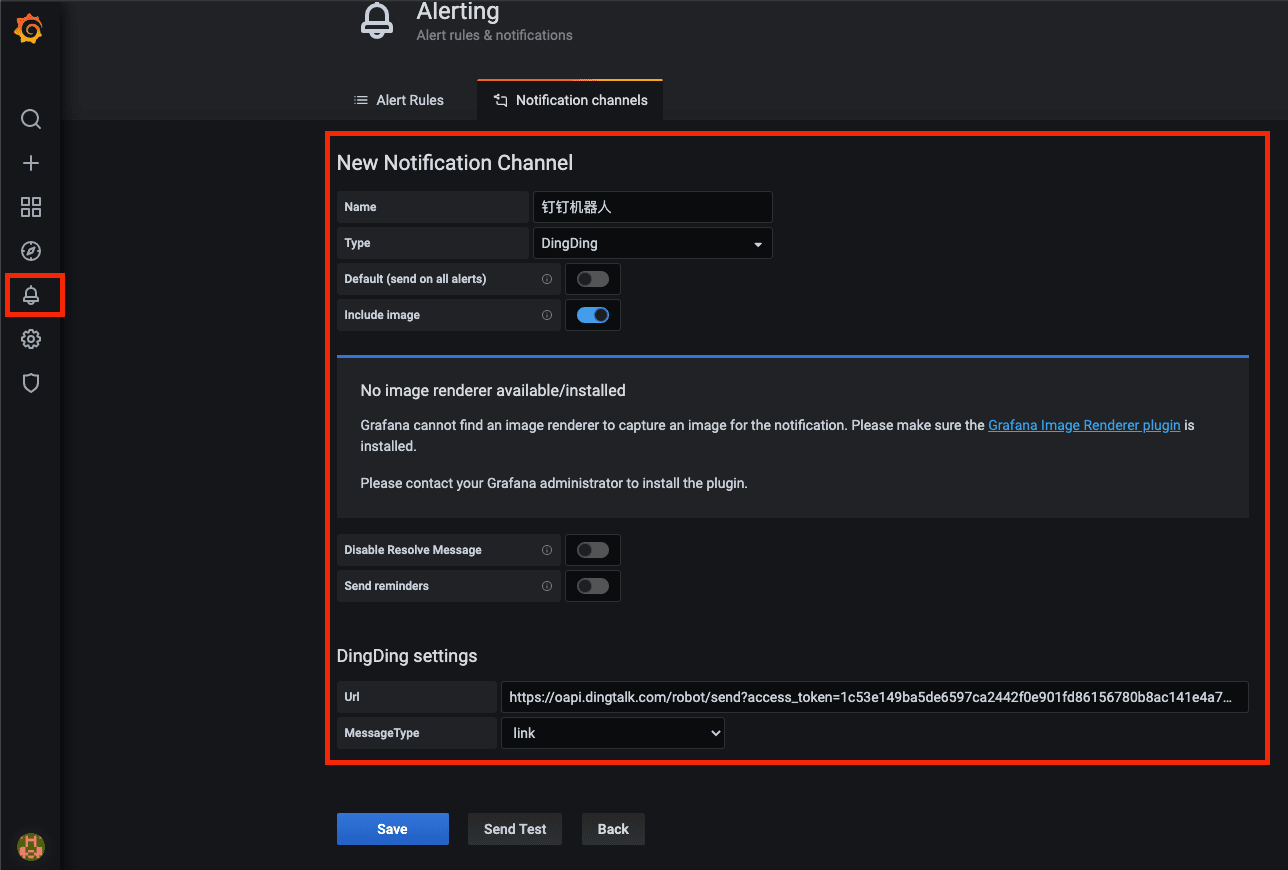
注:这里需要注意的是,Grafana 的钉钉通知没有新版机器人的加签设置,所以推荐使用自定义关键词(由于这里做报警的,每个通知消息都会包含 alert, 所以关键字可设置为 alert)。
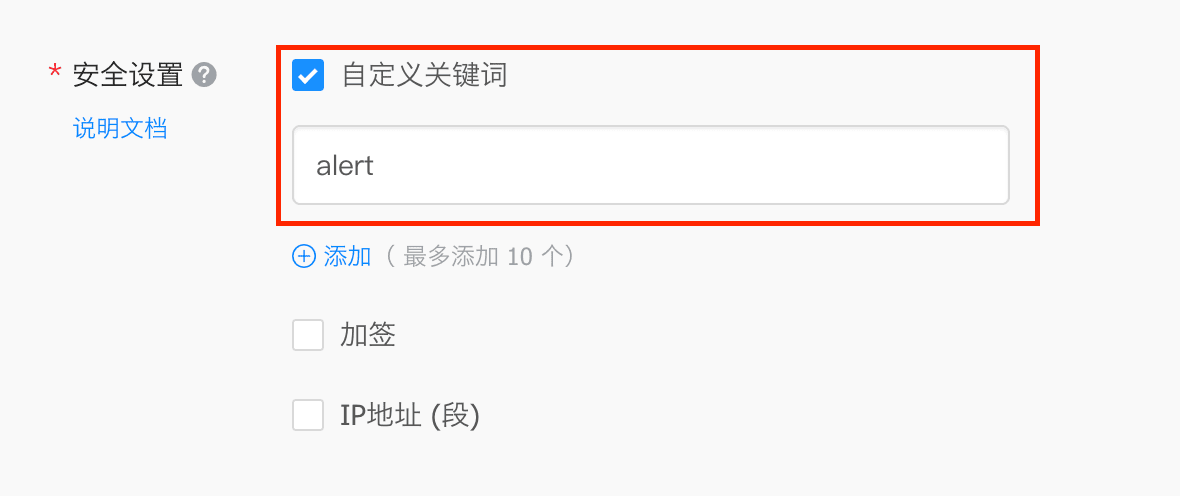
Graph
目前,只有 Graph 支持报警功能。下面新建一个 Dashbaord,在里面创建 Graph。
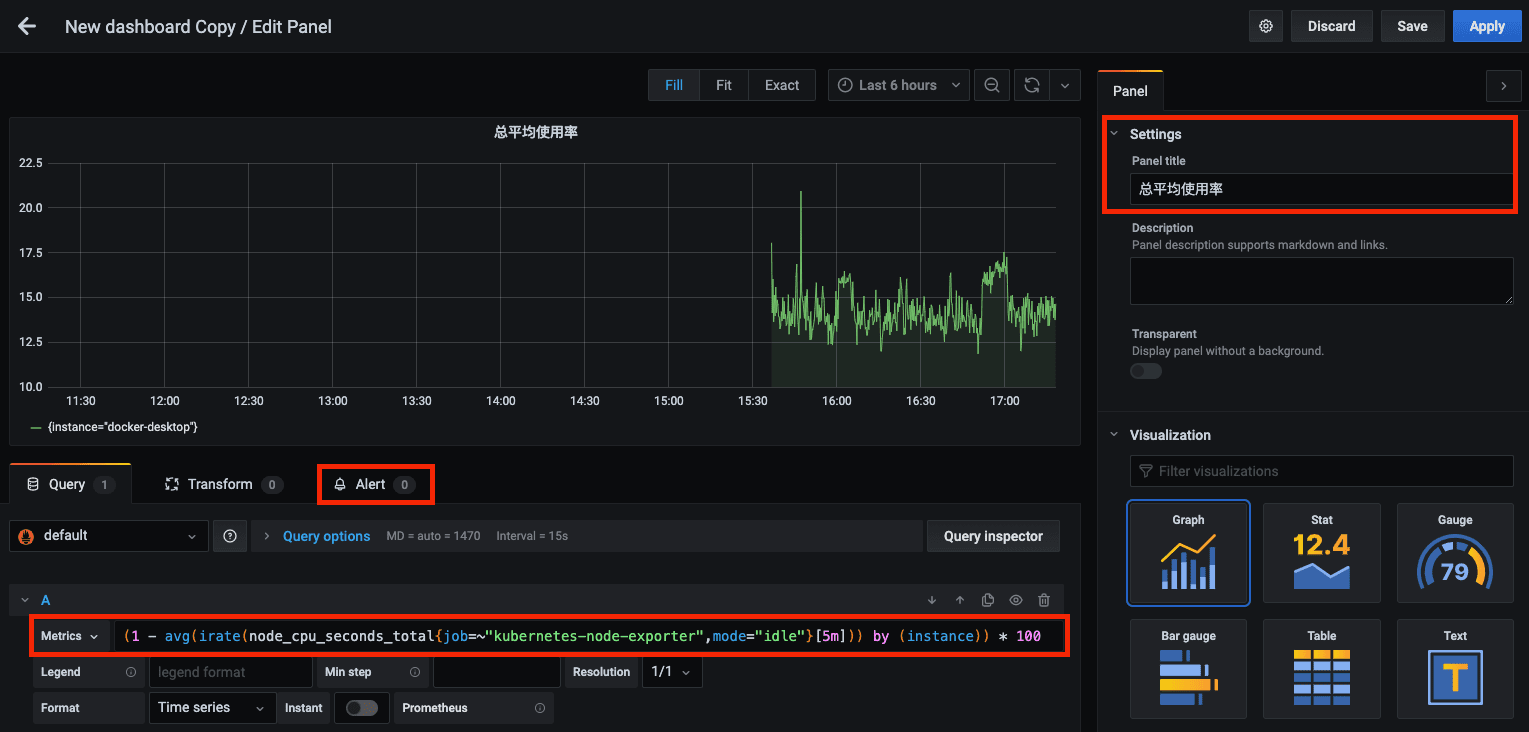
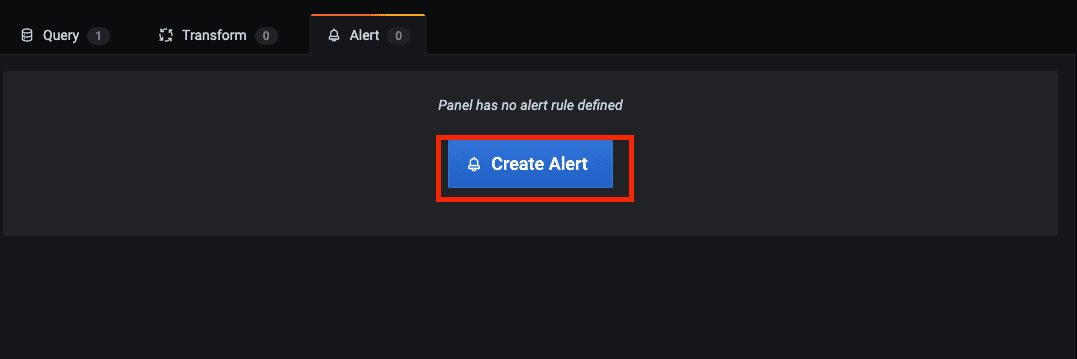
如上图,设置的指标值为 (1 - avg(irate(node_cpu_seconds_total{job=~"kubernetes-node-exporter",mode="idle"}[5m])) by (instance)) * 100 表示节点 cpu 总平均使用率。然后,点击 Alert,创建一个报警。
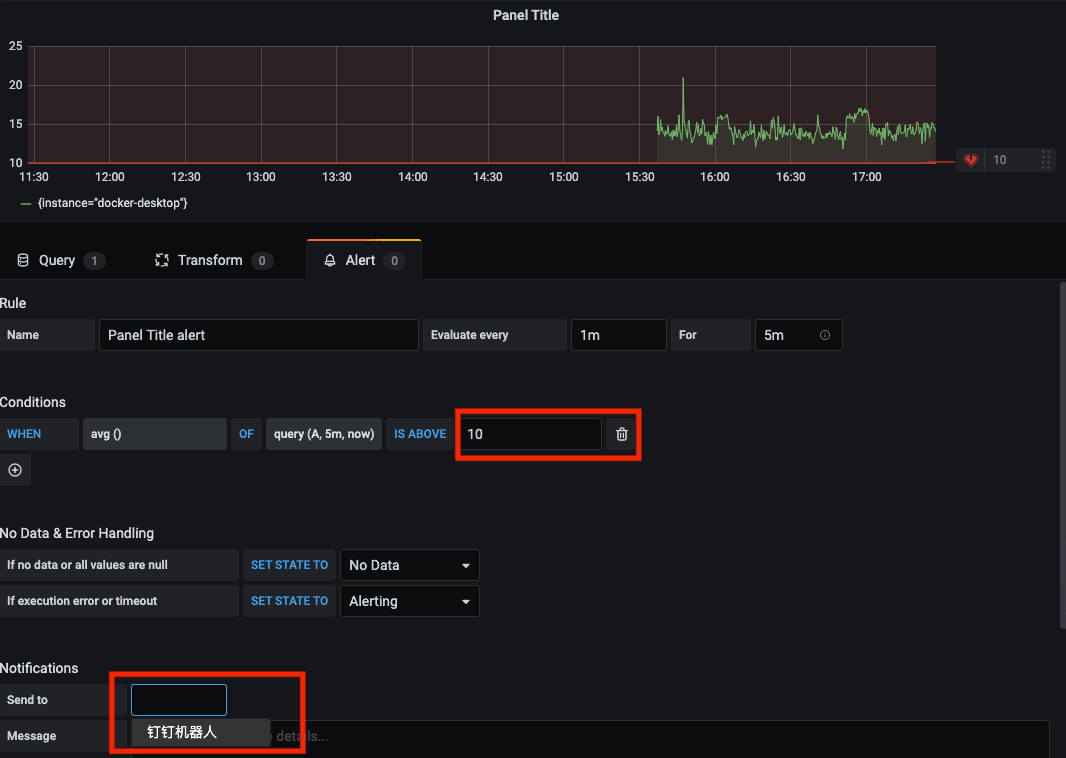
如上图,为了便于触发通知,这里设置了当 cpu 总平均使用率高于 10% 的时候通知到钉钉群。
完成配置后,等到 Rule 周期到的时候(上面设置了 5 分钟),就能在钉钉群中收到报警。
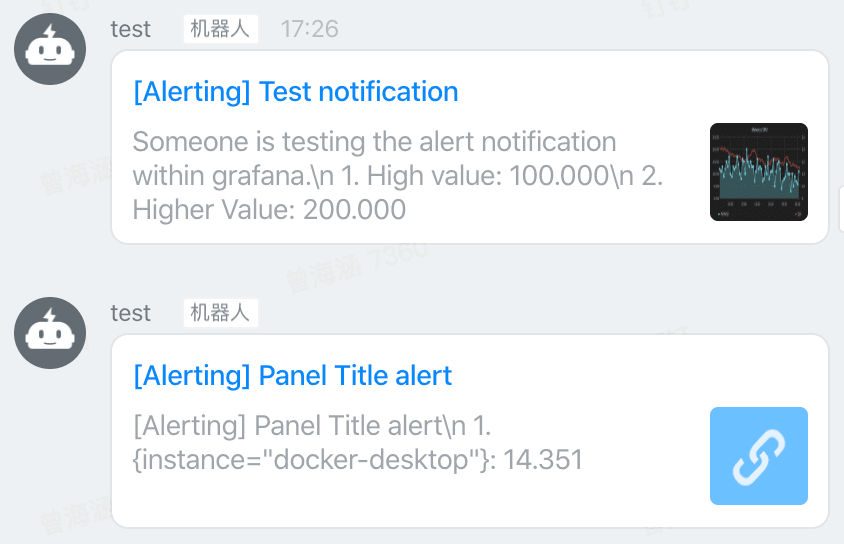
小结
本篇为大家介绍了如何使用 Grafana 可视化 Prometheus 收集到的指标,并设置报警。
注:本章内容涉及的 yaml 文件可前往 https://github.com/MakeOptim/service-mesh/prometheus 获取。
 微服务监控 - 监控自己的服务
微服务监控 - 监控自己的服务