机器学习数据集为大家介绍了什么是数据集,如何收集数据集;机器学习计算机视觉基础 为大家介绍了图像在计算机中如何表达和操作的;本文将为大家介绍如何在 TensorFlow 中加载数据集。
创建项目
从 https://github.com/CatchZeng/YiAI-examples/releases/download/1.0.0/Glory.of.Kings.zip 下载数据集,将下载的 Glory.of.Kings.zip 解压。创建 load-dataset 项目,并将解压后的数据集拷贝到项目中。

注:代码地址 https://github.com/CatchZeng/YiAI-examples/blob/master/load-dataset/load-dataset.ipynb
加载单张图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from tensorflow.keras.preprocessing import image
import numpy as np
def load_image(img_path, target_size):
img = image.load_img(img_path, target_size=target_size)
img_tensor = image.img_to_array(img)
return img_tensor
image_path = f'./Glory of Kings/train/houyi/houyi1.jpg'
img_width = 224
img_height = 224
target_size = (img_width, img_height)
img_tensor = load_image(image_path, target_size)
print(img_tensor.shape)
1
(224, 224, 3)
tf.keras.preprocessing.image 模块提供了加载图像和图像增强的一些工具,在数据集预处理中经常用到。这里,先使用 load_img 从文件中加载图像为 PIL format。然后,通过 img_to_array 将 PIL format 转换为 Numpy array。
显示单张图
1
2
3
4
5
6
7
8
9
10
11
import matplotlib.pyplot as plt
def show_image(img_tensor):
print(f'img_tensor:{img_tensor[0][0]}')
show_tensor = img_tensor/255.
print(f'show_tensor:{show_tensor[0][0]}')
plt.imshow(show_tensor)
plt.axis('off')
plt.show()
show_image(img_tensor)
1
2
img_tensor:[31. 43. 65.]
show_tensor:[0.12156863 0.16862746 0.25490198]

matplotlib 是 Python 编程语言及其数值数学扩展包 NumPy 的可视化操作界面。pyplot 是 matplotlib 的一个模块,它提供了一个类似 MATLAB 的接口。
imshow 方法支持
- (M,N):具有标量数据的图像。使用归一化和颜色图将这些值映射到颜色。
- (M,N,3):具有 RGB 值(0-1 浮点或0-255 整数)的图像。
- (M,N,4):具有 RGBA 值(0-1 浮点或0-255 整数)的图像,即包括透明度。
由于 img_to_array 返回值默认为 float32,所以无法直接使用 imshow 显示。因此,这里直接使用 img_tensor/255. 为图像数据做归一化。
加载数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import tensorflow as tf
data_dir = f"./Glory of Kings/train"
batch_size = 9
img_height = 224
img_width = 224
validation_split=0.2
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=validation_split,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=validation_split,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
print(train_ds)
1
2
3
4
5
6
Found 3607 files belonging to 3 classes.
Using 2886 files for training.
Found 3607 files belonging to 3 classes.
Using 721 files for validation.
['houyi', 'kai', 'wangzhaojun']
<BatchDataset shapes: ((None, 224, 224, 3), (None,)), types: (tf.float32, tf.int32)>
tf.keras.preprocessing 提供了 image_dataset_from_directory方法,便于我们从目录中加载数据集。
参数:
- validation_split:机器学习数据集提过数据集一般分为训练集、验证集、测试集,而训练的时候需要训练集和验证集。validation_split 的意思是将
data_dir目录的所有图片的百分之多少划分为验证集。这里设置为 0.2 表示,20% 为验证集,80% 为训练集。 - subset:可取值为
"training"或者"validation"分别表示训练集和验证集。 - seed:可选随机种子
- batch_size:批量数据的大小。默认值:32
image_dataset_from_directory 返回值是 tf.data.Dataset,是一个包含图像和标签数据的元组 (images, labels),其 images 的形状为 (batch_size, image_size[0], image_size[1], num_channels)。
显示数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
import matplotlib.pyplot as plt
import math
plt.figure(figsize=(10, 10))
cols = 3
for images, labels in train_ds.take(1):
rows = math.ceil(len(images)/cols)
for i in range(len(images)):
plt.subplot(rows, cols, i + 1)
show_tensor = images[i].numpy()/255.
plt.imshow(show_tensor)
plt.title(class_names[labels[i]])
plt.axis("off")

tf.data.Dataset 提供了 take 方法来按 batch_size 分批取数据。这里的 count 设置为 1 表示取 1 次批量(batch_size)大小的数据,batch_size 为 9 所以,取出了 9 张图片。
plt.subplot 的作用是把一个绘图区域(可以理解成画布)分成多个小区域,用来绘制多个子图。
数据输入管道
1
2
3
4
5
6
7
AUTOTUNE = tf.data.AUTOTUNE
train_ds_count = len(np.concatenate([i for x, i in train_ds], axis=0))
print(train_ds_count)
train_ds = train_ds.cache().shuffle(train_ds_count).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
cache
cache 的作用是缓存数据集中的元素。第一次迭代(iterated)数据集时,其元素将缓存在指定的文件或内存中,随后的迭代将使用缓存的数据,加快训练速度。
shuffle
shuffle(buffer_size) 的作用是随机洗牌数据集元素,防止数据过拟合。
首先,Dataset 会取所有数据的前 buffer_size 数据项,填充 buffer,如下图
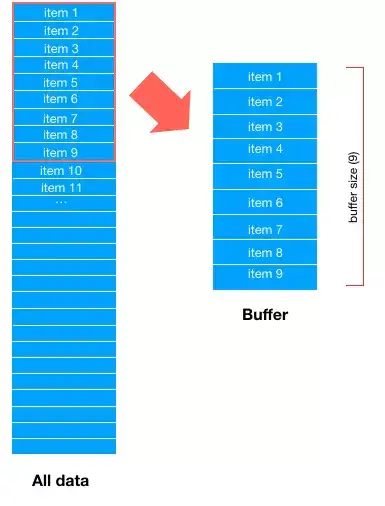
然后,从 buffer 中随机选择一条数据输出,比如这里随机选中了 item 7,那么 buffer 中 item 7 对应的位置就空出来了。
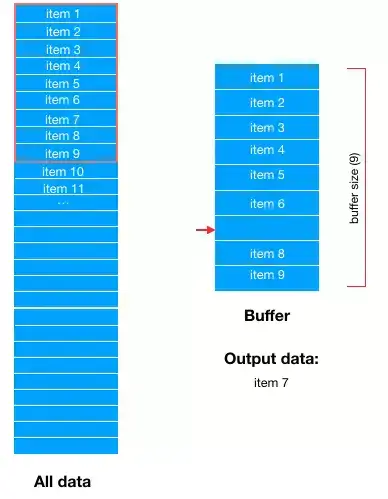
然后在从 Buffer 中随机选择下一条数据输出。

注:这里的数据项
item,并不只是单单一条真实数据,如果有batch size,则一条数据项item包含了batch size条真实数据。
这里,大家可以想象,如果 batch size 取 1,那么就 相当于是顺序输出,这就让 shuffle 毫无意义;如果 batch size 取训练集的大小,那么就可以将数据较好地随机化;当然,大家可以根据自己的数据集情况做调整。
prefetch
prefetch 作用是从数据集中预提取元素,加快训练速度。


小结
本文通过王者荣耀案例的数据集,为大家讲解了如何处理数据集,这不但可以帮助大家看懂王者荣耀案例代码,也有助于大家将前面将的内容串联起来,文中提到的方法在往后的学习和实践中也是非常常用的,需要好好掌握。下一篇开始,笔者将带大家进入期待已久的模型部分的讲解。
参考链接
- https://www.tensorflow.org/guide/data_performance#prefetching
- https://www.tensorflow.org/datasets/performances#caching_the_dataset
- https://stackoverflow.com/questions/63097533/how-to-obtain-the-number-of-files-in-tf-keras-preprocessing-image-dataset-from-d
- https://stackoverflow.com/questions/46444018/meaning-of-buffer-size-in-dataset-map-dataset-prefetch-and-dataset-shuffle
- https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/guide/data_performance.ipynb
 golang 飞书机器人Docker&Jenkinsfile&命令行工具&module
golang 飞书机器人Docker&Jenkinsfile&命令行工具&module