上一篇 讲解了机器学习数据集的概念以及如何收集图片数据集。收集到的数据是被训练的对象,那么怎么表示这些数据呢?数据又需要被怎么操作呢?本文为大家讲解计算机视觉基础,帮助大家在后面的课程中更好地理解和训练模型。
计算机视觉
计算机视觉(Computer vision)是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。
计算机不同于人眼,它需要使用特定的方式来存储和表达图像。
表达
在所有的表达中,最基础的就是像素表达。
黑白图
对于黑白图,图像被转换为 0 或 1 的二元矩阵。该矩阵的每个元素代表一个像素,0 代表黑,1 代表白。

灰度图
对于灰度图,每个像素代表灰度的“强度”,取值从 0 到 255,0 代表黑,255 代表白。

彩色图
对于彩色图,我们一般要选用一种模式来表达不同颜色。一种常见的方式为 RGB(红、绿、蓝)模型。在 RGB 模型中,任何一个彩色图都可以转化为 RGB 这三种颜色表达的叠加。
注:因为红、绿、蓝是三原色,所以可以利用它们的叠加表达任何颜色。
RGB 分别代表三种不同的通道(Channel),每个通道就是原始图像在这个通道(颜色)下的表达。每个通道是一个矩阵,所以,RGB 就是三个矩阵叠加在一起的张量。

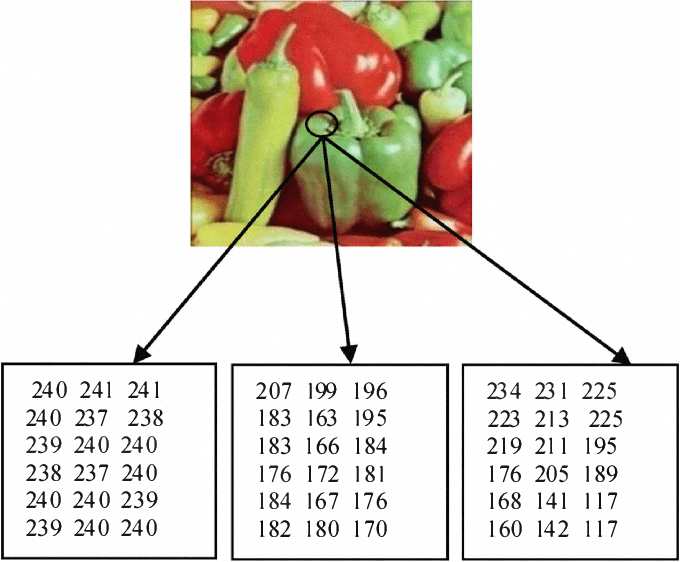
针对像素,大家需要有一个概念,就是像素本身是对真实世界的“采样”。我们把像素用一个整数(0 - 255)来表达,这就意味着将世界的连续信号采样到离散的像素中,一定会有失真。而不同的分辨率,就会带来程度不同的像素表达。所以,大家可以看到近些年,手机相机的像素一直再提升,就是为了能让减少失真。
操作
通过以上的描述,大家已经明白计算机图像其实就是线性代数中的某种张量(矩阵)的表示。那么线性代数上的矩阵操作就可以运用到计算机图像中了。
卷积

上图中,使用 3x3 的矩阵,围绕着该矩阵的中心点,从上到下,从左到右,与原始图(绿色像素)的像素做“內积”得到结果图(蓝色像素)像素,这个操作就叫做卷积。这里的 3x3 矩阵被称为卷积核(Kernel),中心点被称为锚点(Anchor)。
大家可以想到,结果图具体长什么样,取决于这个卷积核中的每个元素值和与原始图像素做的操作(比如:內积)。
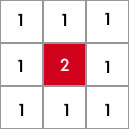
均值滤波
现在有一个卷积核如下图所示,并定义与原始图像素做的操作为內积后的平均值。
将这个卷积运用在如下图的铠爹身上,发现图片变模糊了。

这其实是因为,卷积核 2 是锚点像素值,周边像素都是 1 ,每一个像素都取周边像素的平均值,那么算起来,就变成都是 1 了。

也就是将目的像素趋近于周边的像素,在图像上,看起来就是变模糊的效果,这就是均值滤波的思想。
大家应该可以想到,如果换一个卷积核 ,或者换一个与原始图像素做的操作,将会产生不一样的效果,比如:锐化、边缘检测、特征提取等。因此,卷积核的本质就像一个滤波器(Filter)。
注:对均值滤波感兴趣的可以阅读 https://xiaozhuanlan.com/topic/6270385194 。
归一化
图像(除黑白图)的像素值取值范围是 0-255。通常地,在训练之前会将其做归一化处理,也就是将 0-255 的值,映射称为 0-1 的浮点数,如下图:
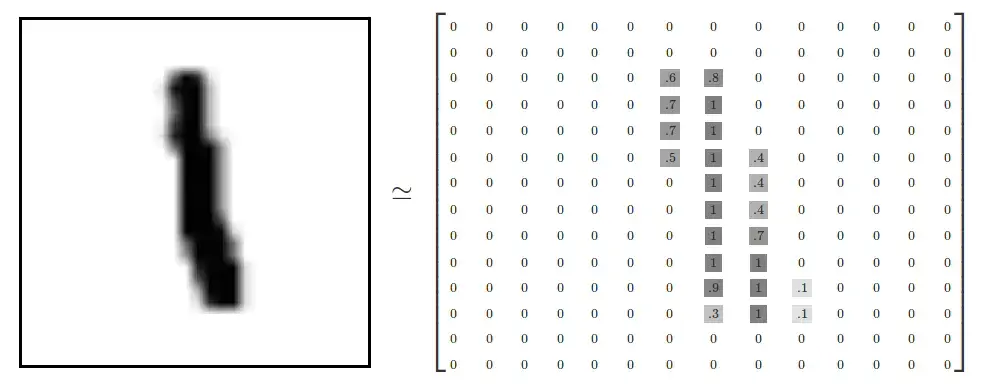
归一化有统一量纲、加速模型训练的优点。
统一量纲
这里举个例子,如果有一个评测健康的公式:健康值 = 身高 + 体重,那么张三身高 1.5 体重 80 和李四身高 1.8 体重 79.7 的健康值尽然是一样的。所以,如果数据量纲不一致,数据值大的维度,将会严重影响结果。 如果我们使用归一化,将身高的范围设置为 1.4-2.0,体重的范围设置为 50-100,然后做归一化,那么张三的健康值为
(1.5-1.4)/(2.0-1.4) + (80-50)/(100-50) = 0.7666
李四的健康值为
(1.8-1.4)/(2.0-1.4) + (79.7-50)/(100-50) = 1.26
这就能较好地区分开来。
在统计学中,归一化的具体作用是归纳统一样本的统计分布性。
加速模型训练
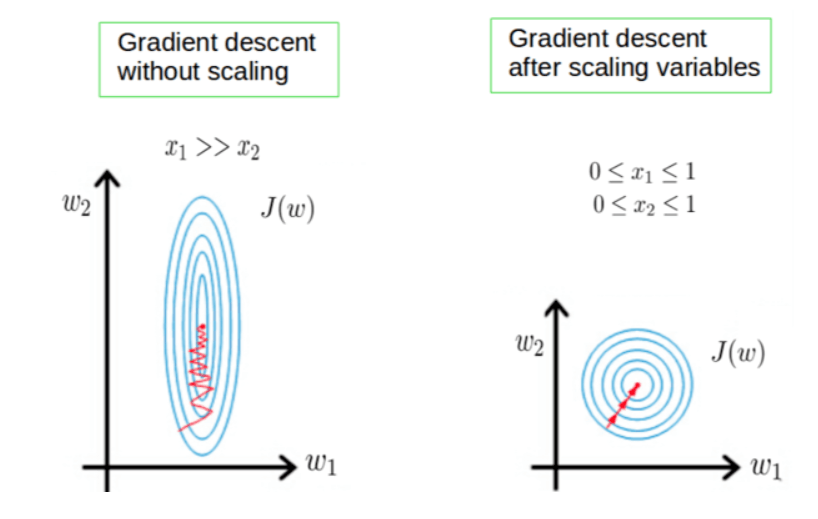
梯度下降
如果不进行归一化,那么由于特征向量中不同特征的取值相差较大,会导致目标函数变“扁”。这样在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路,即训练时间过长。如果进行归一化以后,目标函数会呈现比较“圆”,这样训练速度大大加快,少走很多弯路。
详细可以参考 https://laptrinhx.com/feature-scaling-normalization-standardization-and-scaling-3065876141
GPU 浮点运算
机器学习普遍使用 GPU 训练,而 GPU 的浮点运算速度是比 CPU 快非常多,所以不需要担心浮点运算影响性能。
CPU 与 GPU 浮点运算速度区别主要是来自于硬件架构上的区别。

上图中 ALU 就是“算术逻辑单元(Arithmetic logic unit)”。CPU 和 GPU 进行计算的部分都是 ALU。GPU 绝大部分的芯片面积都是 ALU,而且是超大阵列排布的 ALU。这些 ALU 都是可以并行运行的,所以浮点计算速度就特别高了。相比起来,CPU 大多数面积都需要给控制单元和 Cache,因为 CPU 要承担整个计算机的控制工作,没有 GPU 那么单纯,所以速度比较慢。
另外,int 和 float 的加减运算都是 4 个时钟周期,应该是一样快。但是,float 乘除法比 int 乘除法快, 特别是在 GPU 有浮点协处理器时,浮点除法只会编译成 1 条指令,所以速度比处理整数还快。
小结
本文讲解了计算机图像的表达和操作,以及归一化。这些计算机视觉基础,在图像类机器学习的数据预处理和加载中都会用到,大家需要好好吸收。下一篇,笔者将带大家,进入 Notebook 用本文讲解的知识,说明数据预处理和加载部分的代码。
 易 AI - 机器学习数据集(王者荣耀)
易 AI - 机器学习数据集(王者荣耀)