前言
上一篇 笔者以 MNIST 为例介绍了机器学习开发流程,相信大家对机器学习开发已经有一个大致的了解。
但是,MNIST 这个例子与真实的项目比起来,显得太简单了,流程也不全。一般地,真实项目的图片是 RGB 三通道的,训练的数据集也是自己采集的。
因此,本文开始,笔者带大家做一个王者荣耀英雄识别的案例,效果如下图:
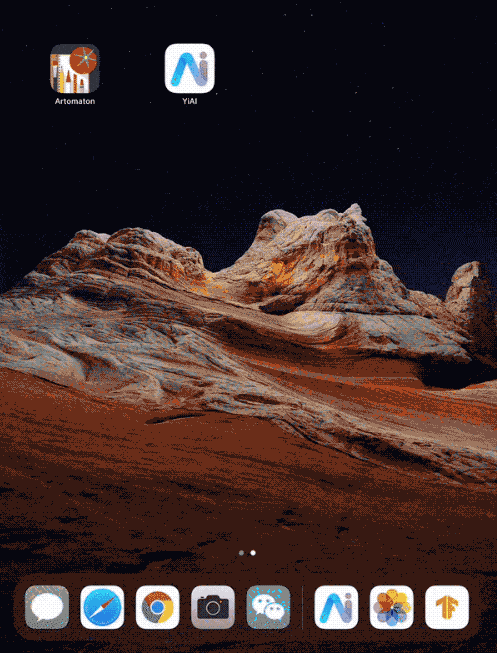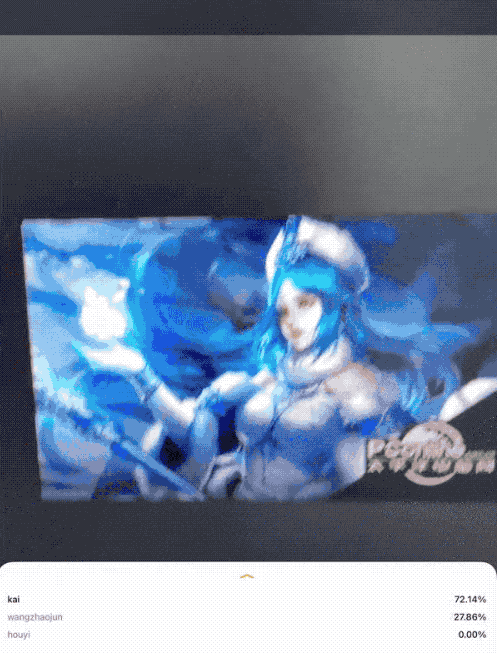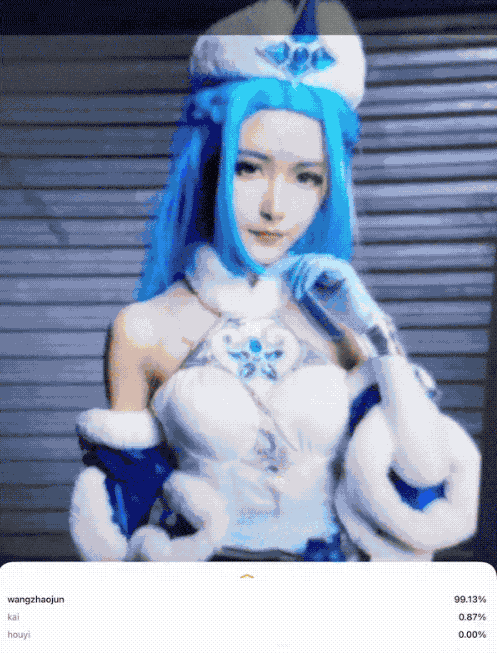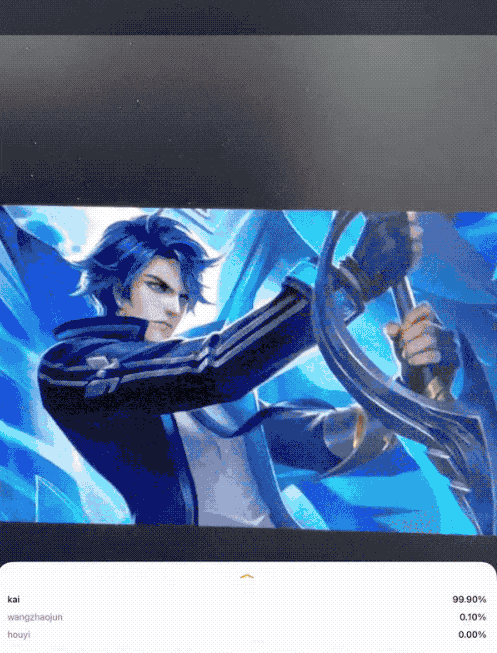
问题构建(识别王者荣耀英雄)环节接下来就是获取数据,也就是采集数据集。
数据集
机器学习关键是训练,训练的“材料”是数据。在这个数据为王的时代,数据即价值。
分类
数据集一般分为训练集、验证集、测试集。
- 训练集:上课学知识
- 验证集:课后练习题,用来纠正和强化所学知识
- 测试集:考试,评估学习效果
划分
数据集的划分方法并没有明确的规定,不过可以参考以下原则:
- 小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。
- 大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
- 超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集。
注:超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。比如:学习率、深层神经网络隐藏层数、树的数量或树的深度。
常用数据集
Fashion-MNIST

Fashion-MNIST 包含 60,000 个训练图像和 10,000 个测试图像,它是一个类似 MNIST 的时尚产品数据库。开发人员认为 MNIST 已被过度使用,因此他们将其作为该数据集的直接替代品。每张图片都以灰度显示,并与 10 个类别的标签相关联。
CIFAR-10

CIFAR-10 数据集是图像分类的另一个数据集,它由 10 个类的 60,000 个图像组成(每个类在上面的图像中表示为一行)。总共有 50,000 个训练图像和 10,000 个测试图像。数据集分为 6 个部分:5 个训练批次和 1 个测试批次,每批有 10,000 个图像。
ImageNet

ImageNet 是根据 WordNet 层次结构组织的图像数据集。WordNet 包含大约 100,000 个单词,ImageNet 平均提供了大约 1000 个图像来说明每个单词。
注:本文重点不在介绍常用数据集,这里不再赘述,更多请参考 keras 提供的可直接加载的数据集 https://www.tensorflow.org/api_docs/python/tf/keras/datasets 。
数据收集
不是所有数据集都是可以通过 keras API 直接加载的。比如,王者荣耀英雄识别这个案例的数据集,就是需要自己收集的。
但是,应该怎么收集呢?手动整理慢,成本也高。为了解决这个问题,笔者做了一个便捷的工具 bing_images 用于从 Bing.com 获取图像 URL 并下载。
下面,介绍如何使用 bing_images 收集王者荣耀数据集。
注:bing_images 的安装和使用方法,可以参考 https://makeoptim.com/deep-learning/collect-image-dataset ,这里不再赘述。
下载图片
download.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from bing_images import bing
from file import rename_files
heros = {
"铠": "kai",
"后羿": "houyi",
"王昭君": "wangzhaojun"
}
if __name__ == '__main__':
for (key, value) in heros.items():
query = f'王者荣耀 {key}'
output_dir = f'../dataset/{value}'
bing.download_images(query,
150,
output_dir= output_dir,
pool_size=5,
force_replace=True)
for value in heros.values():
output_dir = f'../dataset/{value}'
rename_files(output_dir,value,1)
1
python download.py
数据清洗
由于下载的图片有些是 gif、图片内容出错、有干扰信息等问题,因此,还需要手动整理下。
gif
gif 在训练的时候,无法作为输入,可以直接删除 或者可以使用工具提取照片。如果是在 Mac 下可以使用 Gif Preview 提取图片。
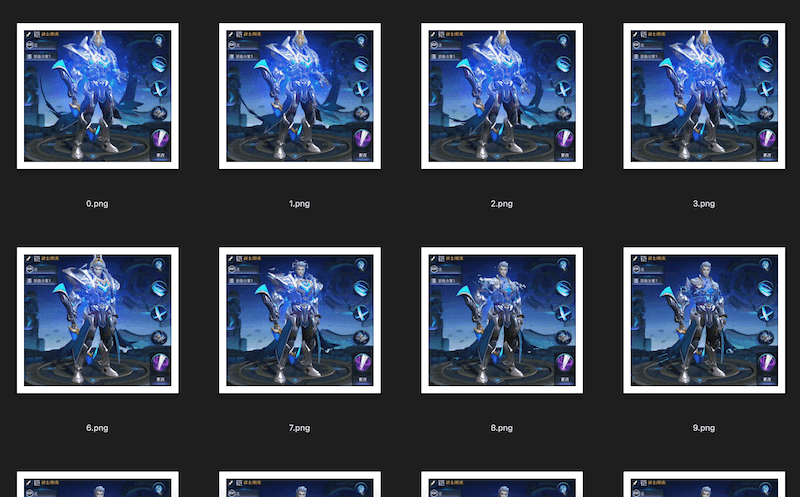
内容出错
如下图,出现在后羿的数据集,显然不对,直接删除。

有干扰信息
如下图,铠爹的妹子就不要出现了吧 😓 。

裁剪后如下图:

如果遇到实在干扰太强的,如下图,马爸爸和猴哥都来了,那就直接删除吧。

其他处理
- 删除隐藏文件
- 转换格式化为 JPG(固定通道数)
- 调整图片大小(太大的图片,影响训练的速度)
- 删除文件损坏的图片
- 图像增强(通过图片的变换,来增加样本集的数量,不然单单 150 张图片是不够做样本集的)
注: 本文重点讲解数据集,图像增强等后续文章再展开讲解。
以上的处理,笔者写了一个脚本,直接处理
process.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
from file import rename_files
from image import reformat_images, resize_images, generate_in_dir, datagen
import random
import string
heros = {
"铠": "kai",
"后羿": "houyi",
"王昭君": "wangzhaojun"
}
def process_images(
src_dir,
dest_dir="",
format="jpg",
remove_old=False,
remove_unavailable=False,
max_w=512,
max_h=512,
rename_prefix="f",
rename_start_index=0,
generator=datagen,
gen_flag='_aug_',
gen_target_size=(224, 224),
gen_num=10,
force_replace=False,
log=False,
):
rename_files(dest_dir, ran_name(), rename_start_index, False)
reformat_images(src_dir, dest_dir, format,
remove_old, remove_unavailable, force_replace, log)
resize_images(dest_dir, dest_dir, max_w, max_h, force_replace, log)
rename_files(dest_dir, ran_name(), rename_start_index, False)
generate_in_dir(dest_dir, dest_dir, generator, gen_flag,
gen_target_size, gen_num, force_replace, log)
rename_files(dest_dir, rename_prefix, rename_start_index, log)
def ran_name():
name = ''.join(random.sample(string.ascii_letters + string.digits, 8))
return name
if __name__ == '__main__':
for (key, value) in heros.items():
src_dir = f'../dataset/{value}'
process_images(src_dir, src_dir, remove_old=True,
remove_unavailable=True, rename_prefix=value, rename_start_index=1)
1
python process.py
注:本案例的代码地址 https://github.com/CatchZeng/YiAI-examples/tree/master/Glory-of-Kings/dataset-collector 。
最后,按 20% 的比例提取测试集合,形成数据集
1
2
3
4
5
6
7
8
├── test
│ ├── houyi(248)
│ ├── wangzhaojun(344)
│ └── kai(311)
└── train
├── houyi(995)
├── wangzhaojun(1372)
└── kai(1240)
注:整理后的数据集,可以从 https://github.com/CatchZeng/YiAI-examples/releases/tag/1.0.0 下载。
训练模型
详见 CNN
部署模型
详见 ios
小结
本文通过王者荣耀英雄识别的案例,介绍了机器学习数据集的概念,并且介绍了常用的数据集,大家可以通过常用数据集来熟悉数据集的结构。但是,笔者还是建议大家可以动手实践一下数据的收集、清洗等过程,做一个自己的数据集。
下一篇开始,笔者将带大家了解,如何训练模型,咱们下一篇见。
 易 AI - 机器学习开发流程
易 AI - 机器学习开发流程