学习上,兴趣是最好的老师。学习机器学习,案例是最好的老师。
一般地,机器学习开发流程如下图所示:

本文以 MNIST 为例,讲解如何实践机器学习开发流程,部署后的效果如下图所示:

注:
- 本例问题构建已经明确,故没有这一步
- 获取数据与探索并准备数据,由于 Keras 一并提供了,故也没有这一步
- 这两部分再后续的其他例子中会补充
MNIST
MNIST 是一个入门级的计算机视觉数据集,它包含各种手写数字图片。在机器学习中的地位相当于编程语言入门的 Hello World。

该数据集包含以下内容:
- train-images-idx3-ubyte.gz: 训练集-图片,6w
- train-labels-idx1-ubyte.gz: 训练集-标签,6w
- t10k-images-idx3-ubyte.gz: 测试集-图片,1w
- t10k-labels-idx1-ubyte.gz: 测试集-标签,1w
图片
MNIST 数据集里的每张图片大小为 28 * 28 像素,可以用 28 * 28 的大小的矩阵来表示一张图片。
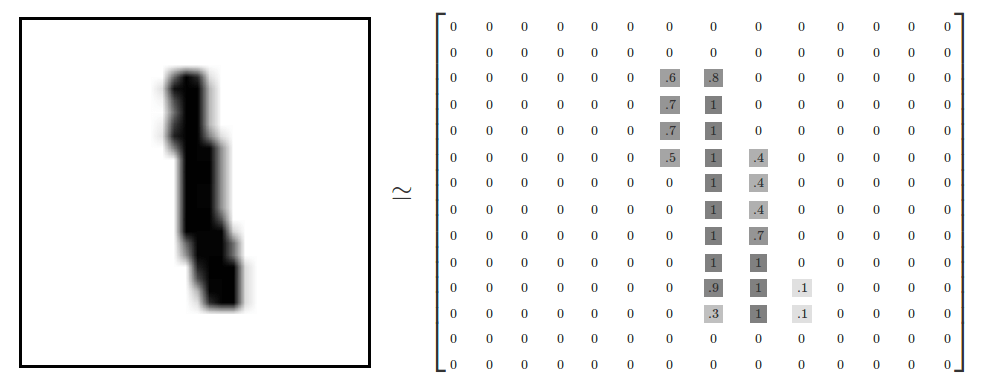
标签
标签用大小为 10(0-9 10 种分类) 的数组(向量)来表示,这种编码我们称之为 One-hot 编码。
One-hot
One-hot 使用 N 位代表 N 种状态,任意时候只有其中一位有效。

以 MNIST 为例,总的有 10 种数字,也就是有 10 中状态
1
2
9 = [0,0,0,0,0,0,0,0,0,1]
1 = [0,1,0,0,0,0,0,0,0,0]
优点
- 能够处理非连续型数值特征
- 在一定程度上也扩充了特征。比如数字本身是一个特征,经过编码以后,就变成了 0-9 10 个特征。
在机器学习工作原理提过模型是有准确率的,也就是说模型给的输出,不一定是 100% 的,用术语来讲叫置信度。
比如,模型预测你书写的数字,20% 的可能是 8,70% 可能是 6,10% 可能是 9,那么模型的最大可能输出就是 6,它的置信度是 70%。
这个时候,One-hot 的优势就表现出来了,编码相当容易:[0,0,0,0,0,0,0.7,0,0.2,0.1]。
张量
在上面的数据表示中,出现过标量(scalar)、向量(vector)、矩阵(matrix),大家应该还听过张量(tensor)。
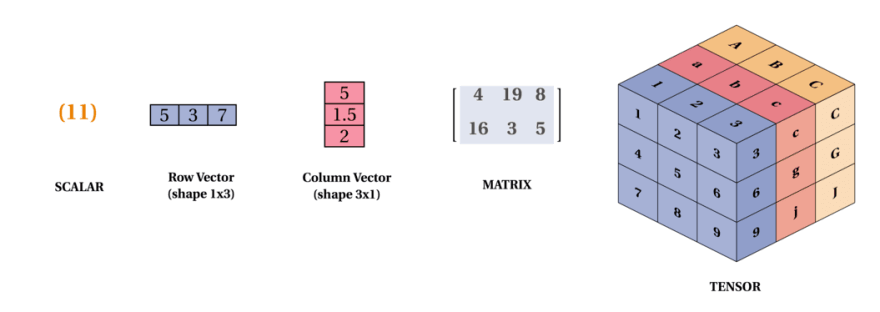
大家可以这样简单去理解:
- 标量是 0 阶张量;向量是 1 阶张量;矩阵是 2 阶张量
- 标量是点的表示;向量是线的表示;矩阵是面的表示;张量是体的表示
- 机器学习中,几乎所有计算都是张量计算,所以 TensorFlow 会以 Tensor 前缀来命名。
- 在 TensorFlow 中一般使用
numpy.ndarray来表示张量。
开发流程
下面,直接进入实际的项目代码,感受下整体的开发流程。
使用 jupyter lab 打开环境,然后导入 https://github.com/CatchZeng/YiAI-examples/blob/master/MNIST/mnist.ipynb 。
准备数据集
Keras 提供了便捷的 API 下载 MNIST 数据集, 并切分为训练和测试集。
注:这里可以使用
type和shape查看数据的具体类型和形状,加深对上述知识点的理解。
1
2
3
4
5
6
7
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print(f'train_iamge type:{type(train_images)} shape:{train_images.shape}')
print(f'train_labels type:{type(train_labels)} shape:{train_labels.shape}')
print(train_images[0])
print(train_labels[0])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
train_iamge type:<class 'numpy.ndarray'> shape:(60000, 28, 28)
train_labels type:<class 'numpy.ndarray'> shape:(60000,)
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
5
定义模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 定义模型
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation=tf.nn.relu),
keras.layers.Conv2D(filters=64, kernel_size=(3, 3), activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Dropout(0.25),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
# 定义如何训练模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 查看模型
model.summary()
注:这里看不懂不要紧,后面会对模型的定义做详细的解释。
训练模型
1
2
# 训练模型
model.fit(train_images, train_labels, epochs=5)
评估模型
1
2
3
4
# 使用测试数据集中的所有图像评估模型。
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
部署
转换模型
由于,本案例的目的是将模型部署到移动端,所以这里需要将模型转换为移动端可以加载的 TF Lite。
1
2
3
4
5
6
7
# Convert Keras model to TF Lite format.
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_float_model = converter.convert()
# Show model size in KBs.
float_model_size = len(tflite_float_model) / 1024
print('Float model size = %dKBs.' % float_model_size)
保存模型(量化可选)
1
2
3
4
5
6
7
8
9
10
11
# Re-convert the model to TF Lite using quantization.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quantized_model = converter.convert()
# Show model size in KBs.
quantized_model_size = len(tflite_quantized_model) / 1024
print('Quantized model size = %dKBs,' % quantized_model_size)
print('which is about %d%% of the float model size.'\
% (quantized_model_size * 100 / float_model_size))
mobile_tflite_quantized_path = f"mnist.tflite"
open(mobile_tflite_quantized_path, "wb").write(tflite_quantized_model)
部署模型
将保存好的模型文件 mnist.tflite 拷贝到 iOS 项目中,pod install 安装完依赖,运行 App 即可。
小结
本文以 MNIST 为例,带大家过了一遍机器学习的开发流程,让大家大致有个印象。其中,你也许对数据集、模型、卷积神经网络、激活函数、Dropout、Flatten、Dense、激活函数、优化器、指标等都不理解,不过不要紧,在后续的文章中,我们将逐一对其讲解,让大家知道卷积神经网络到底是怎么一步一步学会识别的。
 易 AI - 机器学习环境
易 AI - 机器学习环境