机器学习工作原理
机器学习
机器学习其实就是在找一个函数,这里我将这个函数称为“智能函数”,该函数可以接受你的输入,并得到预期的输出。
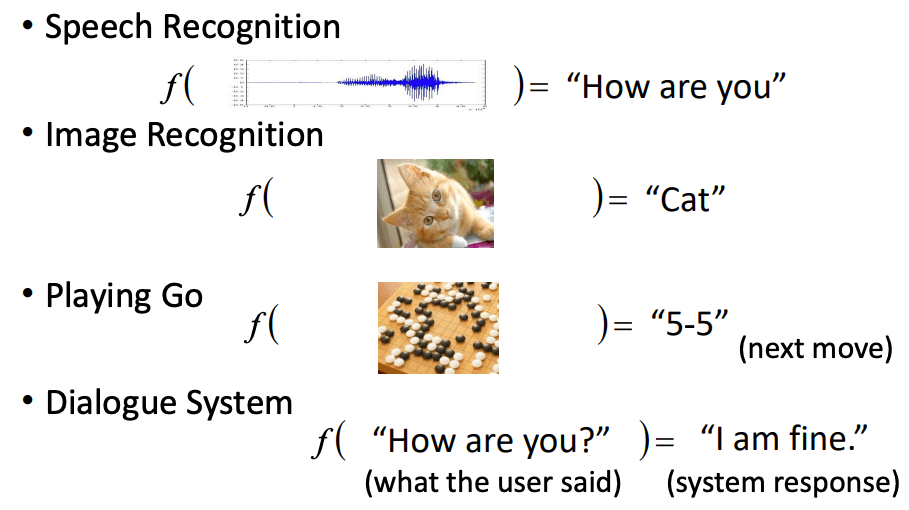
这个函数很复杂,而寻找这个函数的工程就叫做学习。
由于这个函数实在太复杂了,所以,一般我们会使用拟合的方式在实现。这个思想在微积分中叫做“无限接近即确定”,这与泰勒公式的思想极为相似。
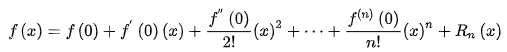
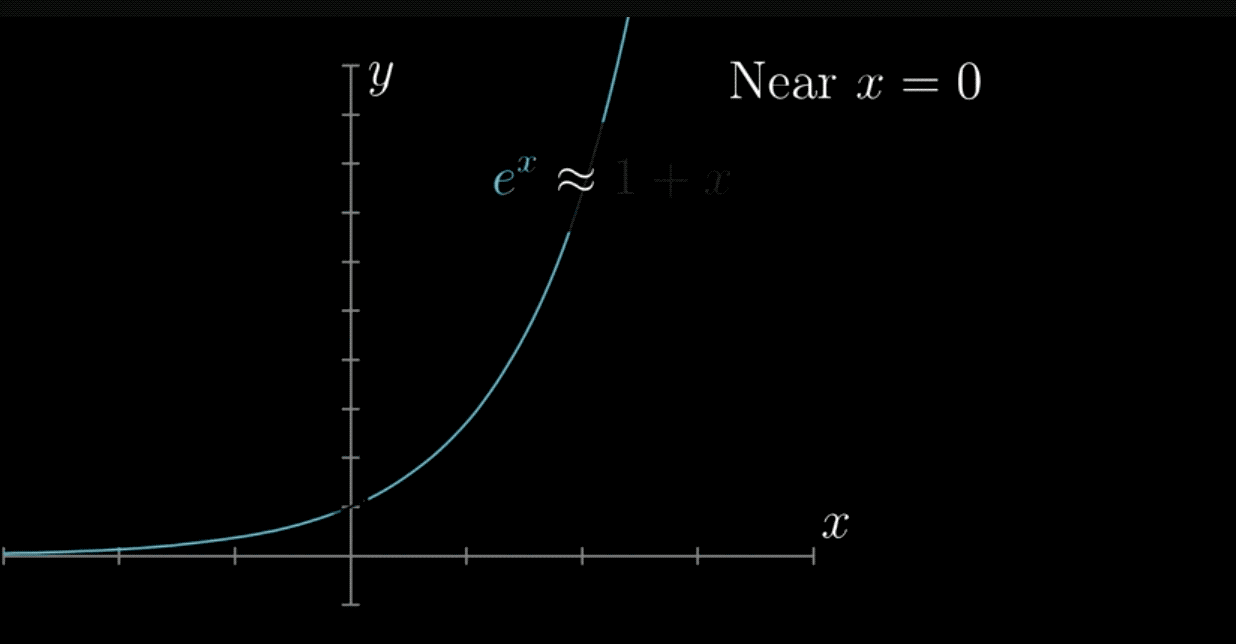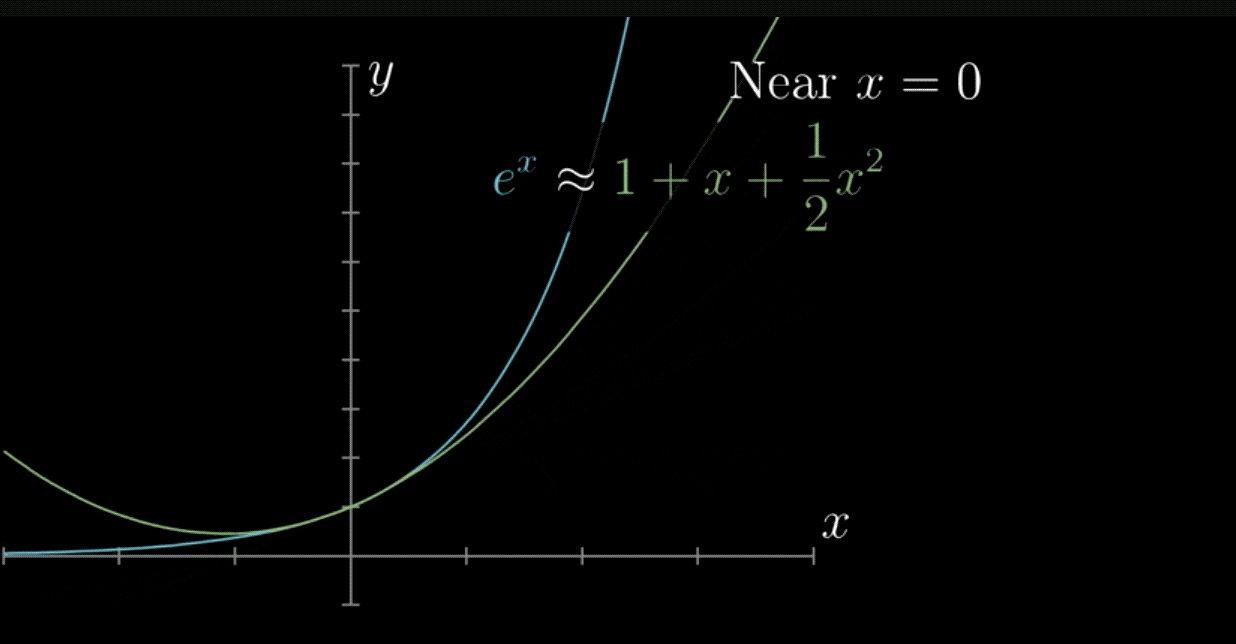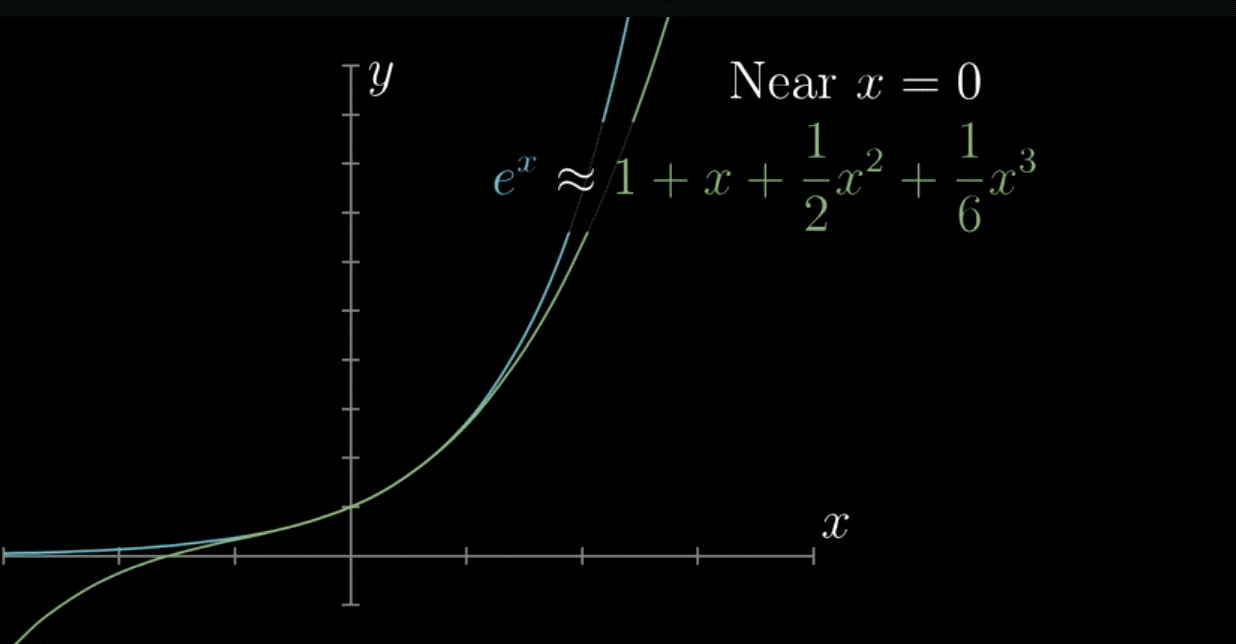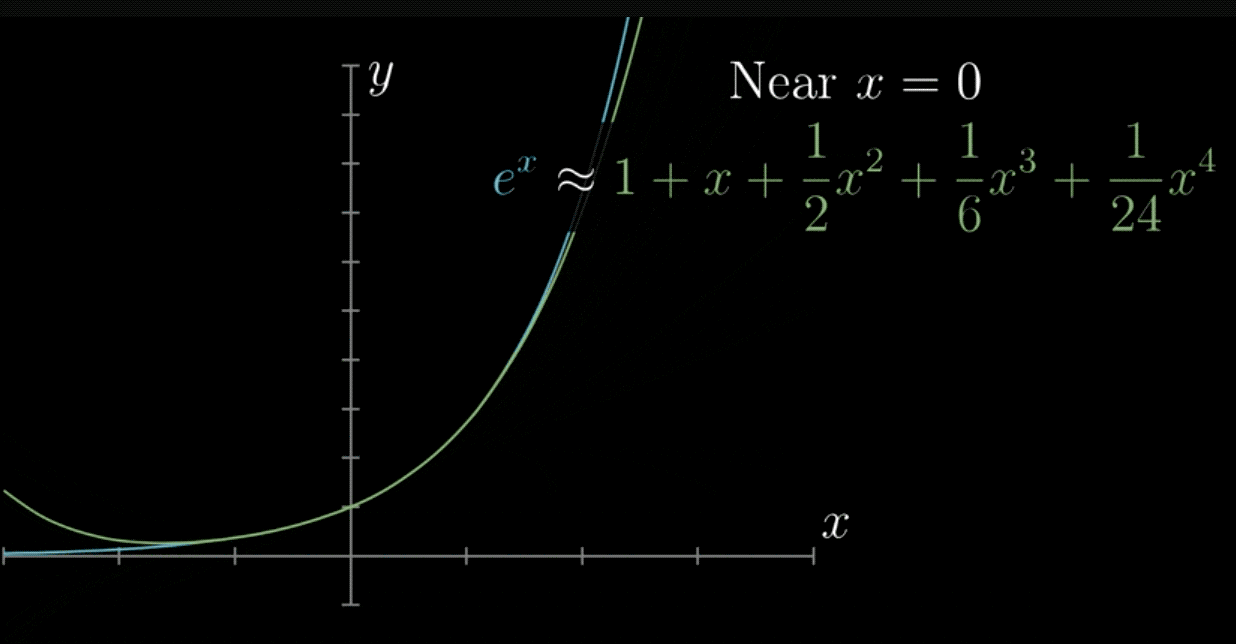
泰勒公式的几何意义就是利用多项式函数来逼近原函数,由于多项式函数可以任意次求导,易于计算,且便于求解极值或者判断函数的性质,因此可以通过泰勒公式获取函数的信息,同时,对于这种近似,必须提供误差分析,来提供近似的可靠性。
因此,你可以简单认为,机器学习就是要使用一堆简单的多项式函数组成的函数集来拟合智能函数。
由于是拟合,所以一定存在偏差,也就导致有模型准确率一说。
而机器学习所要学习的内容其实就是这个函数集的一堆参数。
深度学习
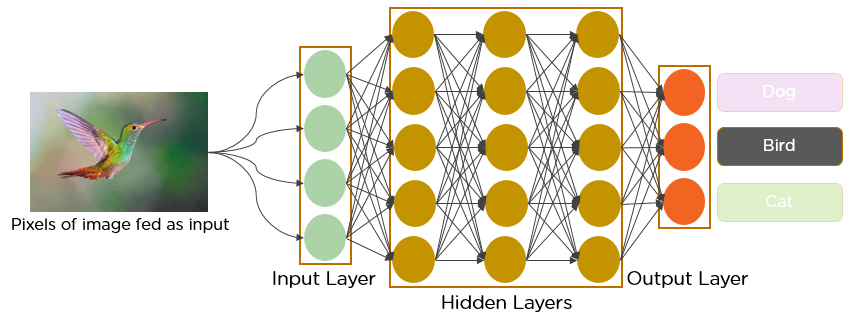
神经网络中每层对输入数据所做的具体操作保存在该层的权重(Weight)中,其本质是一串数字。用术语来说,每层实现的变换由其权重来参数化(Parameterize)。权重有时也被称为该层的参数(Parameter)。在这种语境下,学习的意思是为神经网络的所有层找到一组权重值,使得该网络能够将每个示例输入与其目标正确地一一对应。
但重点来了:一个深度神经网络可能包含数千万个参数。找到所有参数的正确取值可能是一项非常艰巨的任务,特别是考虑到修改某个参数值将会影响其他所有参数的行为。
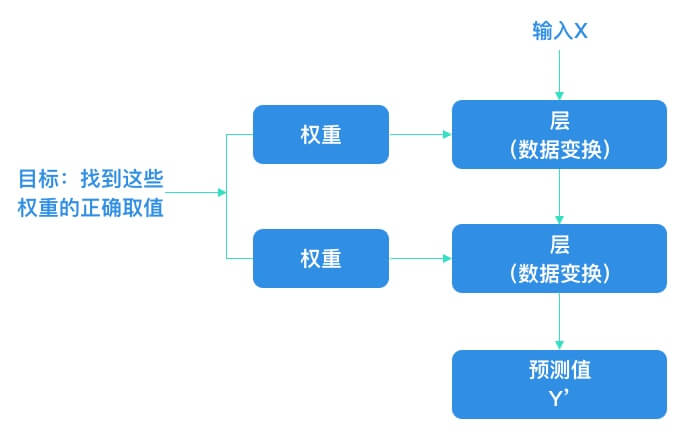
想要控制一件事物,首先需要能够观察它。想要控制神经网络的输出,就需要能够衡量该输出与预期值之间的距离。这是神经网络损失函数(Loss Function) 的任务。损失函数的输入是网络预测值与真实目标值,然后计算一个距离值,衡量该网络在这个示例上的效果好坏。
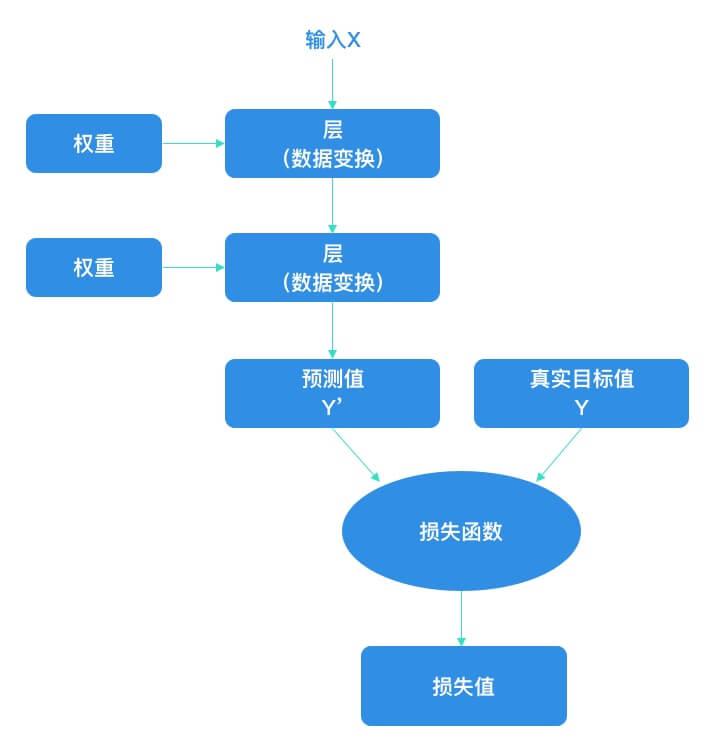
深度学习的基本技巧是利用这个距离值作为反馈信号来对权重值进行微调,以降低当前示例对应的损失值。这种调节由优化器(Optimizer)来完成,它实现了所谓的反向传播(Backpropagation)算法,这是深度学习的核心算法。
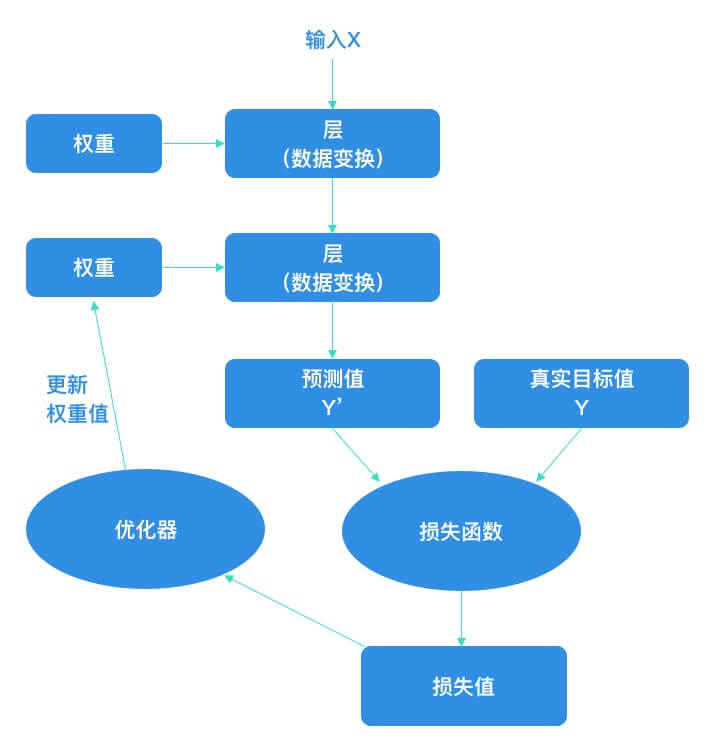
一开始对神经网络的权重随机赋值,因此网络只是实现了一系列随机变换。其输出结果自然也和理想值相去甚远,相应地,损失值也很高。但随着网络处理的示例越来越多,权重值也在向正确的方向逐步微调,损失值也逐渐降低。这就是训练循环(Training Loop),将这种循环重复足够多的次数(通常对数千个示例进行数十次迭代),得到的权重值可以使损失函数最小。具有最小损失的网络,其输出值与目标值尽可能地接近,这就是训练好的网络。
一些理解
- 机器学习本质上是在拟合一个“智能函数”
- 训练的模型,其实是一堆参数
- 想要训练好一个网络,层的设计和损失函数以及优化器是关键
小结
本文为大家简单介绍了机器学习工作原理,旨在帮助大家从宏观上了解机器学习的要素。后续的文章,将会对本文提及的要素做更详尽的解释。
 易 AI - 人工智能基本概念与产业生态
易 AI - 人工智能基本概念与产业生态