
- Foreword
- Object Detection
- Milestone
- TensorFlow Object Detection API
- Create workspace
- Dataset
- Model training
- Summary
- Further reading
- Reference
Foreword
This article will introduce the concept of Object Detection, and explain how to train a custom object detector using TensorFlow Object Detection API through cases, including data set collection and processing, TensorFlow Object Detection API installation, and model training.
The case effect is shown in the figure below:

Object Detection
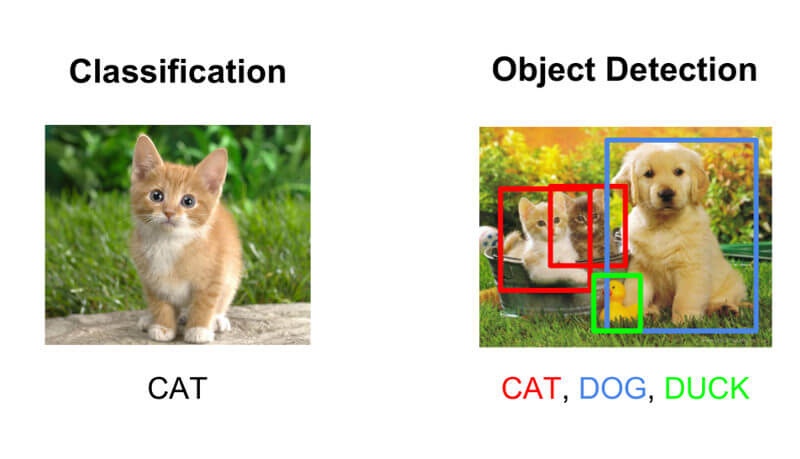
As shown in the figure above, the problem that Image Classification solves is what is the object in the picture, and Object Detection can identify what objects and the location(coordinate) of the object in the picture..
Location
The location information of Object Detection generally has two formats:
- Polar coordinates (xmin, ymin, xmax, ymax):
- xmin,ymin: the minimum value of x,y coordinates
- xmin,ymin: the maximum value of x,y coordinates
- Center point: (x_center, y_center, w, h)
- x_center, y_center: the coordinates of the center point of the target detection frame
- w,h: the width and height of the target detection frame
Note: The upper left corner of the picture is the origin (0,0)
Milestone
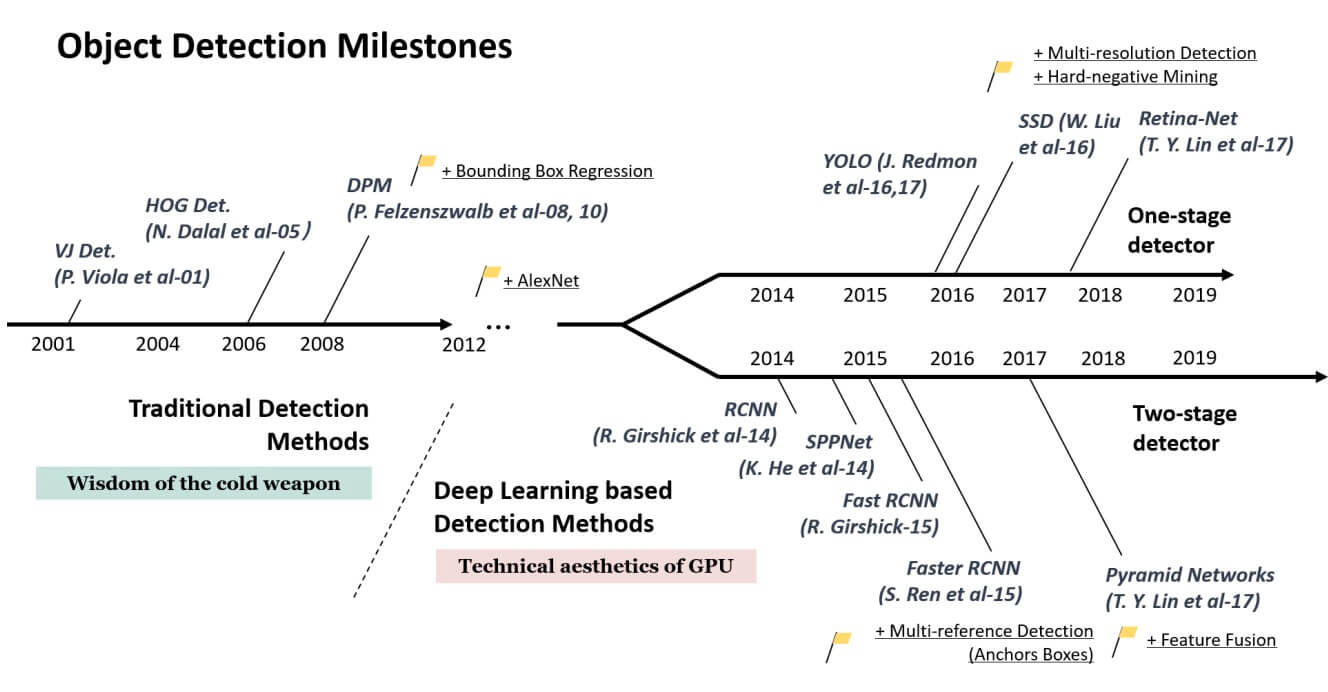
Traditional method (region proposal + manual feature extraction + classifier)
HOG+SVM、DPM
Region Proposal+CNN(Two-stage)
R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN
End-to-End(One-stage)
YOLO、SSD
TensorFlow Object Detection API
The TensorFlow Object Detection API is an open source framework built on top of TensorFlow that makes it easy to construct, train and deploy object detection models. In addition, the TensorFlow Object Detection API also provides Model Zoo to facilitate our selection and switching of pre-trained models.
Install dependencies
Use the following command to check if the installation is successful.
1
2
3
4
$ conda --version
conda 4.9.2
$ protoc --version
libprotoc 3.17.1
Install API
The official installation steps provided by the TensorFlow Object Detection API are more cumbersome. The author wrote a script to install directly in one step.
Execute git clone https://github.com/CatchZeng/object-detection-api.git to download the repo, then go to the directory of the repo (hereafter referred to as the oda repo) and execute the following command, if you see the following output, indicating that the installation was successful.
1
2
3
4
5
6
$ conda create -n od python=3.8.5 && conda activate od && make install
......
----------------------------------------------------------------------
Ran 24 tests in 21.869s
OK (skipped=1)
Note: If you don’t want to use conda, you can install it directly with
make installin your python environment, for example, use it in colab.
Note: The update of
cudaDNNandtoolkitmay not be as fast as TensorFlow. Therefore, if your machine has a GPU, after the installation is complete, you need to downgrade TensorFlow to the version supported bycudaDNNandtoolkitin order to support GPU training. Take2.8.0as an example:
Note: If the installation fails, you can refer to the detailed steps in the official document.
Create workspace
Note: !!! From here, please make sure to execute under the environment of
conda od.
Go to the oda repo directory and execute the following command to create the workspace directory structure.
Note:
SAVE_DIRis the directory to save the workspace, andNAMEis the name of the workspace.
1
$ make workspace-box SAVE_DIR=workspace NAME=test
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
└── workspace
└── test
├── Makefile
├── annotations: Store the labeled data set, including val.record, train.record, label_map.pbtxt
├── convert_quant_lite.py: the script to quantize tflite model
├── export_tflite_graph_tf2.py: the script to export tflite model
├── exported-models: Store the exported model after training
├── exporter_main_v2.py: the script to export model
├── images: Data set images and xml annotations
│ ├── test: Store manual verification images
│ ├── train: Training set images and xml annotations
│ └── val: Evaluation set images and xml annotations
├── model_main_tf2.py:the script to train model
├── models: Custom model
├── pre-trained-models: pre-trained models
└── test_images.py: the script to verify the image manually
Dataset
Images
I like to drink tea. Today I will use a cup, teapot, humidifier as examples.

Put the collected pictures into the three subdirectories of images in the project directory.
Note: This case is just to show how to train the Object Detection model, so the dataset is relatively small. In the production, remember to collect as many datasets as possible.
Annotation
After collecting the pictures, you need to annotate the images in the training and evaluation sets.
We choose LabelImg as the annotation tool.
Install LabelImg according to the instructions of installation, then execute labelImg to select the train and val folders for annotation.
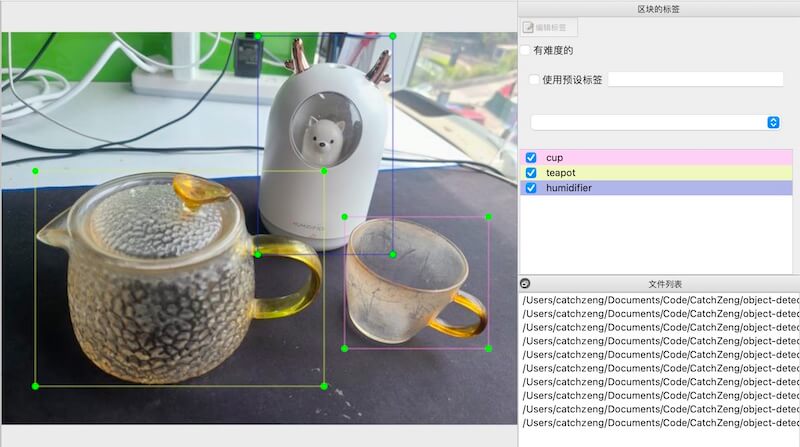
After the annotation is completed, the xml annotation file corresponding to the image will be generated, as shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
workspace/test/images
├── test
│ ├── 15.jpg
│ └── 16.jpg
├── train
│ ├── 1.jpg
│ ├── 1.xml
│ ├── 10.jpg
│ ├── 10.xml
│ ├── 2.jpg
│ ├── 2.xml
│ ├── 3.jpg
│ ├── 3.xml
│ ├── 4.jpg
│ ├── 4.xml
│ ├── 5.jpg
│ ├── 5.xml
│ ├── 6.jpg
│ ├── 6.xml
│ ├── 7.jpg
│ ├── 7.xml
│ ├── 8.jpg
│ ├── 8.xml
│ ├── 9.jpg
│ └── 9.xml
└── val
├── 11.jpg
├── 11.xml
├── 12.jpg
├── 12.xml
├── 13.jpg
├── 13.xml
├── 14.jpg
└── 14.xml
Create TFRecord
TensorFlow Object Detection API only supports TFRecord format, therefore, the dataset needs to be converted.
Go to the workspace directory (cd workspace/test), and then execute make gen-tfrecord, it will generate label_map.pbtxt and TFRecord format dataset in the annotations folder.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
$ make gen-tfrecord
python gen_label_map.py
unsorted: ['cup', 'teapot', 'humidifier']
sorted: ['cup', 'humidifier', 'teapot']
item {
id: 1
name: 'cup'
}
item {
id: 2
name: 'humidifier'
}
item {
id: 3
name: 'teapot'
}
python generate_tfrecord.py \
-x images/train \
-l annotations/label_map.pbtxt \
-o annotations/train.record
Successfully created the TFRecord file: annotations/train.record
python generate_tfrecord.py \
-x images/val \
-l annotations/label_map.pbtxt \
-o annotations/val.record
Successfully created the TFRecord file: annotations/val.record
1
2
3
4
annotations
├── label_map.pbtxt
├── train.record
└── val.record
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# label_map.pbtxt
item {
id: 1
name: 'cup'
}
item {
id: 2
name: 'humidifier'
}
item {
id: 3
name: 'teapot'
}
Model training
Note: !!! From here, please make sure you have go to the workspace directory (
cd workspace/test).
Download the pre-trained model
Select the appropriate model from Model Zoo, download and unzip it and put it in workspace/test/pre-trained-models.
If you choose SSD MobileNet V2 FPNLite 320x320, you can execute the following command to automatically download and decompress
1
$ make dl-model
The directory structure is as follows:
1
2
3
4
5
6
└── test
└── pre-trained-models
└── ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8
├── checkpoint
├── pipeline.config
└── saved_model
Configure training pipeline
Create a corresponding model folder in the models directory, for example: ssd_mobilenet_v2_fpnlite_320x320, and copy pre-trained-models/ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8/pipeline.config.
1
2
3
4
5
└── test
├── models
│ └── ssd_mobilenet_v2_fpnlite_320x320
│ └── pipeline.config
└── pre-trained-models
Among them, pipeline.config needs to be modified according to the project as follows
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
model {
ssd {
num_classes: 3 # Modify to the number of objects that need to be identified.
......
}
train_config {
batch_size: 8 # Here you need to adjust the size according to your own computer performance
......
optimizer {
momentum_optimizer {
learning_rate {
cosine_decay_learning_rate {
learning_rate_base: 0.07999999821186066
total_steps: 10000 # Modify to the total number of steps you want to train
warmup_learning_rate: 0.026666000485420227
warmup_steps: 1000
}
}
momentum_optimizer_value: 0.8999999761581421
}
use_moving_average: false
}
fine_tune_checkpoint: "pre-trained-models/ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8/checkpoint/ckpt-0" # Modify the path to the pre-trained model
num_steps: 10000 # Modify to the total number of steps you want to train
startup_delay_steps: 0.0
replicas_to_aggregate: 8
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
fine_tune_checkpoint_type: "detection" # Here needs to be modified to detection, because we are doing object detection
fine_tune_checkpoint_version: V2
}
train_input_reader {
label_map_path: "annotations/label_map.pbtxt" # Modify to the annotations path
tf_record_input_reader {
input_path: "annotations/train.record" # Modify the path to the training set
}
}
eval_config {
metrics_set: "coco_detection_metrics"
use_moving_averages: false
}
eval_input_reader {
label_map_path: "annotations/label_map.pbtxt" # Modify to the annotations path
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "annotations/val.record" # Modify the path to the evaluation set
}
}
Training model
1
$ make train
Note: If the following problems occur
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
You can execute the following command to solve it.
pip uninstall numpy pip install numpy
Model export and conversion
-
Saved Model
1
$ make export
-
TFLite Model
1
$ make export-lite -
Convert TFLite model
1
$ make convert-lite -
Quantize TFLite Model
1
$ make convert-quant-lite
Note: For the above command, you can add
-640to indicate the use of the model ofSSD MobileNet V2 FPNLite 640x640, for example:make train->make train-640
Testing
After executing make export to export the model, and put the test image in the images/test folder, and then execute python test_images.py to output the annotated image to images/test_annotated.
Summary
This article has gone through the entire process of Object Detection through cases, hoping to help you quickly master the ability to train custom Object Detectors.
The code and dataset of the case have been placed in https://github.com/CatchZeng/object-detection-api.
The following articles will bring you the principles of Object Detection, Popular Object detection networks, and Image Segmentation. That’s it for this article, see you next.
Further reading
- The easiest way to Train a Custom Image Segmentation Model Using TensorFlow Object Detection API Mask R-CNN
- The easiest way to Train a Custom Object Detection Model Using TensorFlow Object Detection API
- How to deploy an image segmentation model service
- The easiest way to train a U-NET Image Segmentation model using TensorFlow and labelme
Reference
- https://github.com/tensorflow/models/tree/master/research/object_detection
- https://arxiv.org/pdf/1905.05055.pdf
- https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md
- https://stackoverflow.com/questions/66060487/valueerror-numpy-ndarray-size-changed-may-indicate-binary-incompatibility-exp
 易 AI - 使用 TensorFlow Object Detection API 训练自定义目标检测模型
易 AI - 使用 TensorFlow Object Detection API 训练自定义目标检测模型