本文将为大家介绍以下人工智能(Artificial Intelligence)相关概念的含义和区别
- 机器学习(Machine Learning)
- 监督学习(Supervised Learning)
- 无监督学习(Unsupervised Learning)
- 强化学习(Reinforcement Learning)
- 深度学习(Deep Learning)
- 迁移学习(Transfer Learning)
- 联邦学习(Federated Learning)

同时,介绍人工智能整个产业的生态,让大家对人工智能有一个基本的认识。
人工智能

人工智能诞生于 20 世纪 50 年代,定义为:努力将通常由人类完成的智力任务自动化。因此,人工智能是一个综合性的领域,不仅包括机器学习,还包括更多不涉及学习的方法。比如,早期的符号主义人工智能(硬编码)、专家系统等。
虽然符号主义人工智能适合用来解决定义明确的逻辑问题,但它难以给出明确的规则来解决更加复杂、模糊的问题,比如图像分类、语音识别和语言翻译。于是出现了一种新的方法来替代符号主义人工智能,这就是机器学习。
机器学习
机器学习是实现人工智能的一种方法。
在经典的程序设计中,人们输入的是规则(即程序)和数据,系统输出的是答案。

而机器学习,输入的是数据和预期得到的答案,系统输出的是规则。这些规则随后可应用于新的数据,并使计算机自主生成答案。

因此,机器学习系统是训练出来的,而不是明确地用程序编写出来的。将与某个任务相关的许多示例输入机器学习系统,它会在这些示例中找到统计结构,从而最终找到规则将任务自动化。
机器学习根据形式可分为:
- 监督学习
- 无监督学习
- 强化学习
监督学习
事先(有经验)为数据标记标签(答案) 的训练形式就是监督学习。训练目标是能够给新数据以正确的标签。
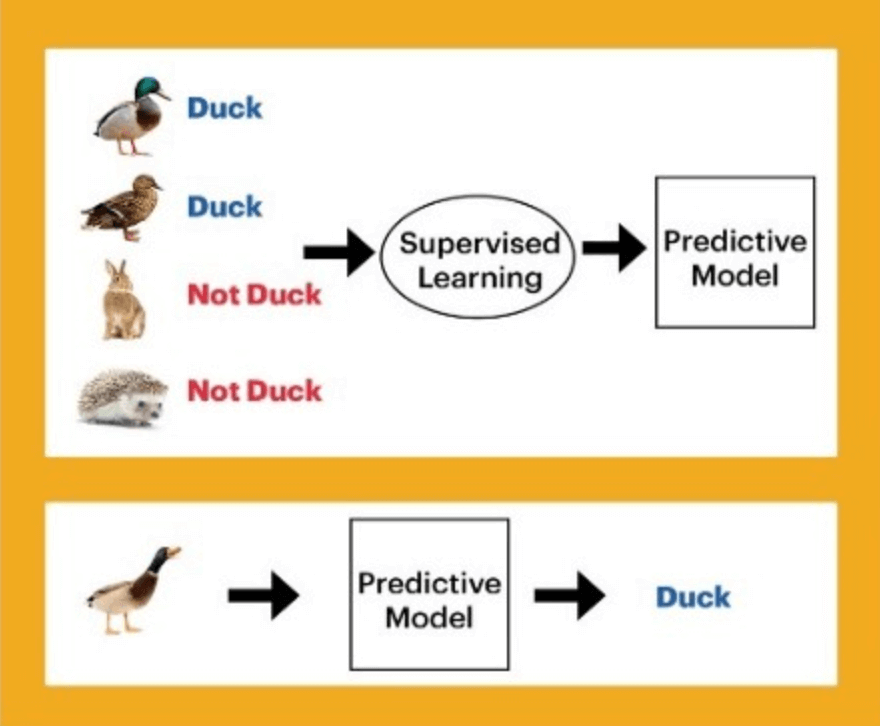
举个例子,妈妈拿了很多鸭子、兔子图片(数据)给小朋友看,并且告诉它这个是鸭子、那个是兔子(标签)。小朋友通过妈妈多次的指导(训练),下次再拿一个新的鸭子图片,就会辨认出来了(找到规则)。
监督学习常用于任务驱动的回归或者分类问题。
无监督学习
当缺乏足够的先验知识,难以标注类别时,根据未加标签的训练数据解决模式识别中的各种问题,称之为无监督学习。

大家都听过“啤酒+尿不湿”的故事,这个故事就是根据用户的购买行为来推荐相关的商品的一个例子。比如大家在淘宝、天猫、京东上逛的时候,总会根据你的浏览行为推荐一些相关的商品,有些商品就是无监督学习通过聚类来推荐出来的。系统会发现一些购买行为相似的用户,推荐这类用户最”喜欢”的商品。
监督学习常用于数据驱动的聚类问题。
强化学习
强化学习强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
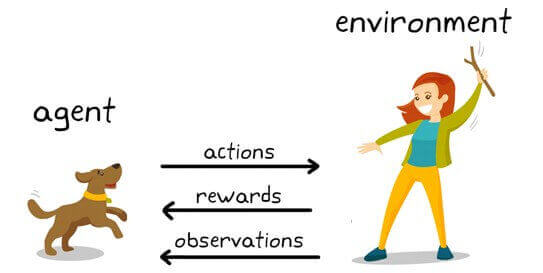
以上图为例,强化学习的目标是训练狗(代理人) 以完成环境中的任务。首先,训练员发出命令或提示,狗会观察。然后狗通过采取行动做出反应。如果动作接近期望的行为,则培训师可能会提供奖励例如食品或玩具。否则,将不会提供任何奖励或否定的奖励。在训练开始时,这只狗可能会采取更多随机动作,例如在给定命令“坐下”时翻身,因为它试图将特定的观察结果与动作和奖励相关联。观察与动作之间的这种关联或映射称为策略。
从狗的角度来看,理想的情况是对每种提示都能正确做出反应,从而使它得到尽可能多的对待。因此,强化学习训练的全部含义是调整狗的策略,以便它学习所需的行为,从而最大程度地提高回报。训练完成后,狗应该能够观察主人并采取适当的行动,例如,在被命令“坐下”时坐下。
一些理解
- 监督学习训练数据有标签,无监督学习训练数据没有标签,强化学习训练数据也没有标签,但是可以通过环境给出的奖惩来学习。
- 监督和无监督学习的学习过程是静态的,强化学习的学习过程是动态的。这里静态与动态的区别在于是否会与环境进行交互。
- 监督和无监督学习解决的更多是类似五官的感知问题,强化学习解决的更多是类似大脑的决策类问题。
深度学习
深度学习是机器学习的一个分支领域,是从数据中学习表示的一种新方法。深度学习强调从连续的层(layer)中进行学习,这些层对应于越来越有意义的表示。
深度学习中的深度指的并不是利用这种方法所获取的更深层次的理解,而是指一系列连续的表示层。数据模型中包含多少层,这被称为模型的深度(depth)。
在深度学习中,这些分层表示几乎总是通过叫作神经网络(Neural Network) 的模型来学习得到的。神经网络的结构是逐层堆叠。
下图为手写体数字识别 MNIST的神经网络
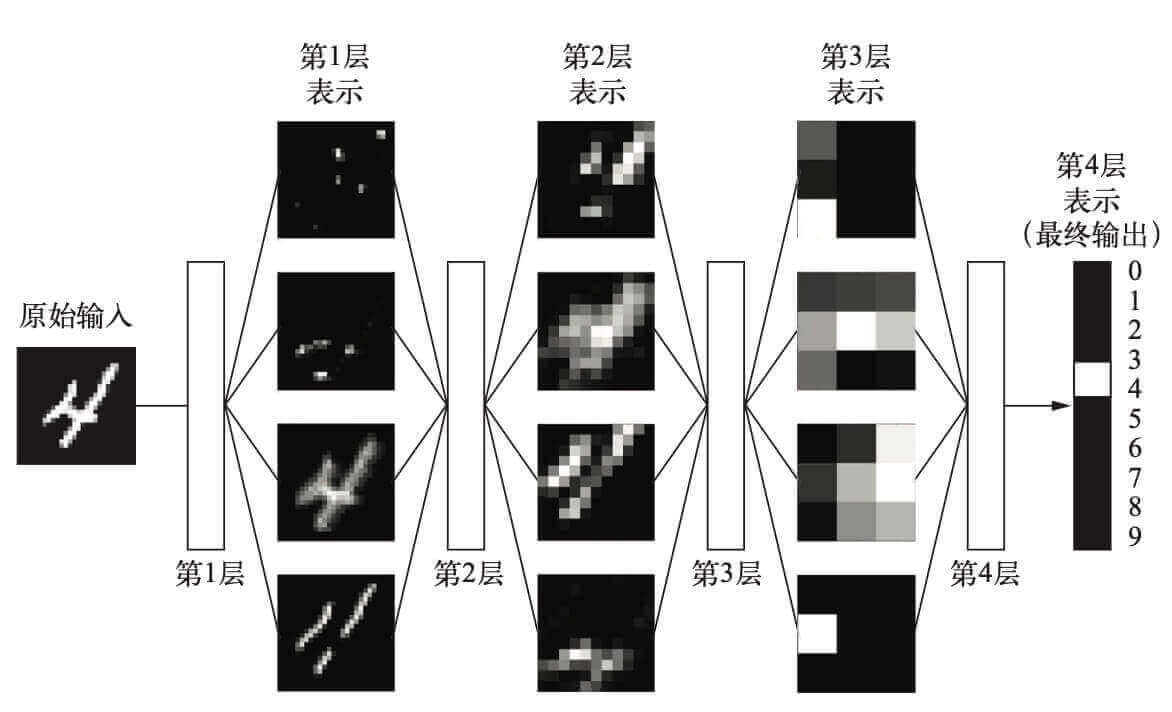
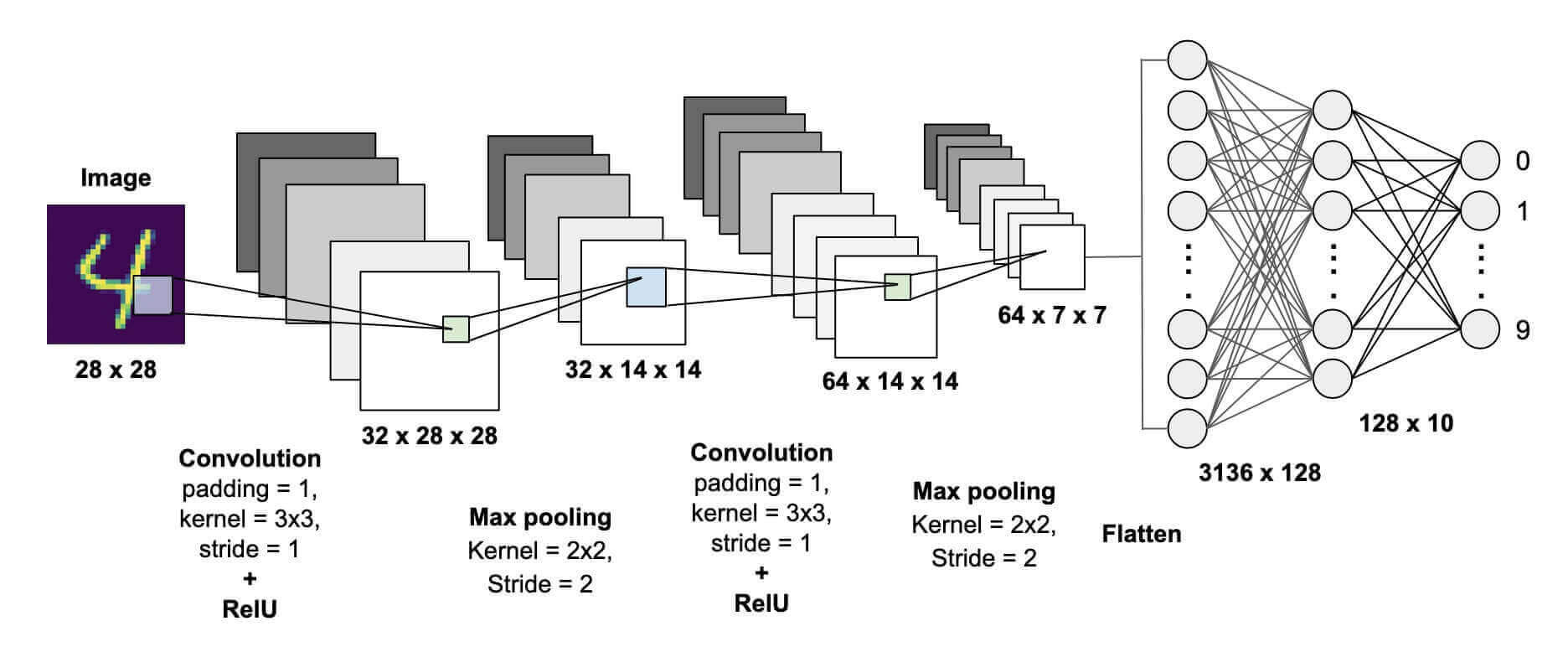
这个神经网络将数字图像转换成与原始图像差别越来越大的表示,而其中关于最终结果的信息却越来越丰富。你可以将深度网络看作多级信息蒸馏操作:信息穿过连续的过滤器,其纯度越来越高(即对任务的帮助越来越大)。
这就是深度学习的技术定义:学习数据表示的多级方法。这个想法很简单,但事实证明,非常简单的机制如果具有足够大的规模,将会产生魔法般的效果。
现在看不懂图中的表示不要紧,后续章节会逐步讲解。
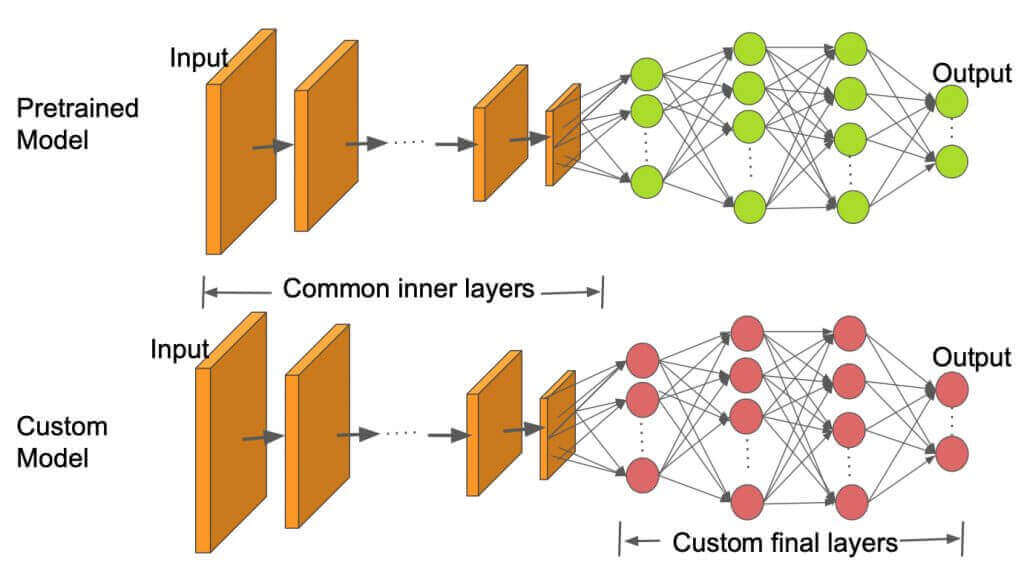
迁移学习
迁移学习是属于机器学习的一种研究领域。它专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习 (Starting From Scratch)。
比如说,用来辨识汽车的模型也可以被用来提升识别卡车的能力。
联邦学习
数据是机器学习的基础。而在大多数行业中,由于行业竞争、隐私安全、行政手续复杂等问题,数据常常是以孤岛的形式存在的。甚至即使是在同一个公司的不同部门之间实现数据集中整合也面临着重重阻力。在现实中想要将分散在各地、各个机构的数据进行整合几乎是不可能的,或者说所需的成本是巨大的。随着人工智能的进一步发展,重视数据隐私和安全已经成为了世界性的趋势。各国都在加强对数据安全和隐私的保护,比如欧盟的法案《通用数据保护条例》(GDPR)。
针对数据孤岛和数据隐私的两难问题,联邦学习便诞生了。联邦学习是一个机器学习框架,能有效帮助多个机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。所以,联邦学习本质上是一种分布式机器学习技术,或机器学习框架。

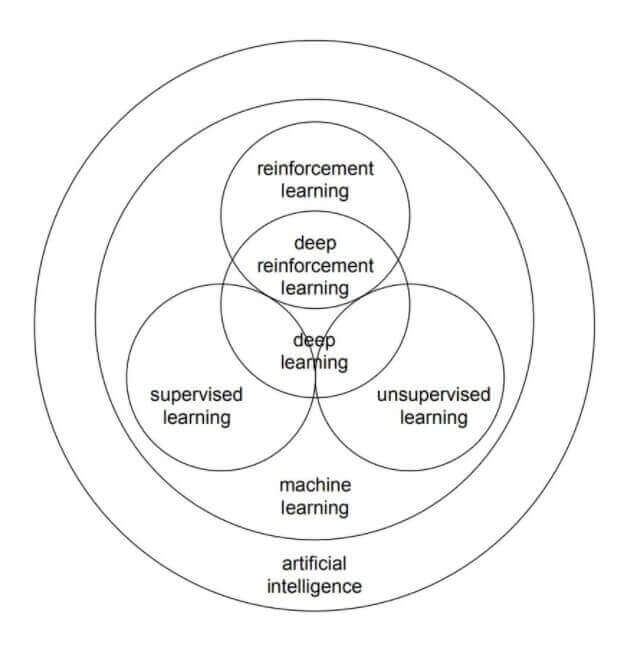
概念间的关系
下图为人工智能相关概念的关系图:
产业生态
理解了人工智能的基本概念后,接着,我们再来看下人工智能的产业生态是什么样的。从全局的视角来了解整个行业,有助于我们知识体系的建立。
人工智能产业,从产业链的上下游关系,可以分为基础层、技术层和应用层。
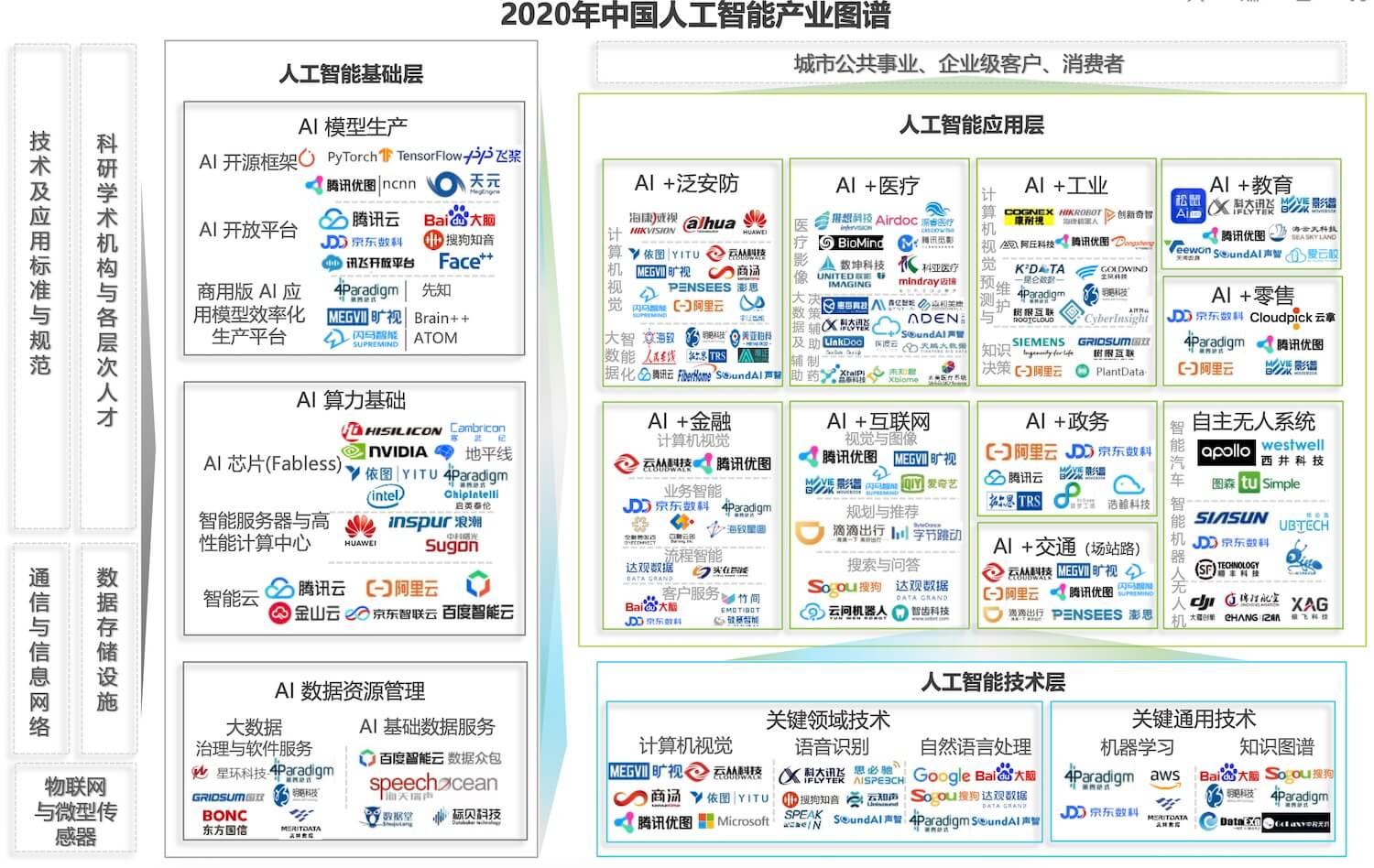
基础层
基础层按照服务的线条被划分成芯片服务、云服务、机器学习平台和数据服务等,它们都是整个 AI 行业最底层服务提供者;
在基础层,讯飞的开放平台、百度大脑、腾讯云是我们接触比较多的机器学习平台,阿里云、百度云是做得比较好的云服务提供商。
技术层
在技术层,按照技术类别分为计算机视觉、语音识别、自然语言处理、知识图谱等;
在技术层,有我们熟悉的“视觉四小龙”(商汤、依图、云从、旷视),主要是提供计算机视觉服务,最常见的应用场景就是人脸识别了;还有科大讯飞、云知声、思必驰等,主要提供语音识别、语音合成、语音分析等服务。
应用层
在应用层,按行业分为零售、金融、教育、工业、互联网、医疗、安防、政务、交通、自主无人系统等;
在应用层,有我们熟悉些大疆无人机、京东的零售、滴滴打车服务、字节跳动的头条推荐等。
全链服务
除了以上讲的几个层,在整个 AI 产业生态中,BAT 等大厂还提供了全链条的服务,它们既做了最底层的基础服务,比如云服务、机器学习平台;也做技术层,比如 BAT 也有自家的计算机视觉、语音识别等能力;同时,它们也有应用层的整套方案,比如百度大脑。
小结
本文是专栏的开篇,本专栏旨在用人话讲 AI。因此,如果大家看到不通俗易懂的可以留言,笔者将不断改进文章的表述,帮助大家更好地了解 AI。
 Golang 专栏
Golang 专栏